
This is part of our Practical Guide to Qualitative Content Analysis | Start a Free Trial of Delve | Take Our Free Online Qualitative Data Analysis Course
Relational content analysis, like most methods of content analysis, begins with a process of counting the occurrence of concepts in a text or set of texts. But as the name suggests, relational analysis goes further than the presence of concepts by exploring relationships between them.
C_oncepts_ in qualitative content analysis are words or sets of words that represent key ideas in the text. In relational analysis, concepts alone hold no inherent meaning. Instead, they are like “ideational kernels” (Carley, 1993) or symbols that acquire meaning through their connections to other symbols.[1] In short, a concept’s meaning is assigned by its relationships to other concepts.
Similarities to other methods of qualitative content analysis
Quantitative Beginnings
What makes content analysis unique is that it requires both a quantitative (Krippendorff, 2004, Neuendorf, 2002) and a qualitative methodology (Berg, 2001) that can be applied in an inductive or a deductive way. That is to say, counting the frequency of concepts is not central to other qualitative methods of research.
While researchers may consider frequency counts to help organize the coding process in other qualitative research methods, they generally do not signify meaning or relevance. In content analysis, frequency counts are core and are typically included as part of the final write-up.
Differences from other methods of qualitative content analysis
Following the initial quantitative steps, the differences between relational analysis and other methods of content analysis are found in how concepts are analyzed in the secondary steps.
As mentioned, relational analysis explores the relationships between concepts. There is no meaning assigned to the concepts in and of themselves. Instead, the relationships between “ideation kernels” (a word or words symbolizing an idea) are what help the researcher to answer their research questions.
Another difference is that other methods of content analysis are generally easier to classify as either manifest vs. latent or inductive vs. deductive ways to analyze data. Relational analysis does not fit as neatly into this hierarchy.
For instance, you may count explicit concepts in the initial steps (manifest analysis) and also assign meaning to the data through inductive analysis. In later stages, you may use latent analysis to add supplemental information you discover from further readings but deductively code your data using a prexisting framework to increase the reliability of your results.
An example of specific methodological differences
Let’s consider the study “Applications of Computer-Aided Text Analysis: Analyzing Literary and Non-Literary Texts” (Palmquist, Carley, and Dale, 1997).
The below section of the study highlights the different results generated from applying both a conceptual and a relational analysis to the same set of texts.
In this example, both students observed a scientist and were asked to write about the experience.
Student A: I found that scientists engage in research in order to make discoveries and generate new ideas. Such research by scientists is hard work and often involves collaboration with other scientists which leads to discoveries that make the scientists famous. Such collaboration may be informal, such as when they share new ideas over lunch, or formal, such as when they are co-authors of a paper.
Student B: It was hard work to research famous scientists engaged in collaboration and I made many informal discoveries. My research showed that scientists engaged in collaboration with other scientists are co-authors of at least one paper containing their new ideas. Some scientists make formal discoveries and have new ideas.
[Conceptual analysis of] explicit concepts may not reveal any significant differences. For example, the existence of “I, scientist, research, hard work, collaboration, discoveries, new ideas, etc…” are explicit in both texts, occurring the same number of times.
Relational analysis […] however, reveals that while all concepts in the text are shared, only five concepts are common to both. Analyzing these statements reveals that Student A reports on what “I” found out about “scientists,” and elaborated on the notion of “scientists” doing “research.” Student B focuses on what “I’s” research was and sees scientists as “making discoveries” without emphasis on research.
Though the same sets of text were analyzed, each approach garnered different results and interpretations. For instance, the relational method contextualized “research” in relation to how it was used to answer the same question; Student A used “research” as a noun—Student B, a verb. The conceptual approach only discerned many times it occurred in both texts.
To summarize, you are only able to derive meaning as far as the explicit data will allow in conceptual analysis. You would only be interested in quantifying concepts, and not in examining how they are related, which is the function of relational content analysis.
But that is not to say that conceptual analysis is “less effective”, only that it is limited by the quantitative nature of its analysis. For example, to identify trends in large amounts of text—such as the frequency of use—conceptual analysis is extremely helpful to indicate larger ideas.
When to use relational content analysis?
To summarize the use cases of relational content analysis, you can employ this methodology in the following research scenarios:
-
To determine if concepts are interrelated (e.g. climate change and sustainable clothing)
-
To analyze large amounts of textual documents.
-
When you want to use both quantitative and qualitative data.
-
To analyze complex models of human thought and language usage.
-
To visualize how multiple concepts interrelate.
-
To provide some understanding of the overall meaning of texts.
-
To explore a text’s deeper semantic meanings.
-
To add an interpretive layer to manifest analyses.
To summarize, you can use relational analysis to maintain a high degree of statistical rigor without losing the richness of detail apparent in even more qualitative methods[1]—such as grounded theory method, narrative analysis, or participatory action research.
Source materials for relational content analysis
Relational content analysis can be used to analyze any occurrence of communicative language that is presented in text form. Data sources include but are not limited to:
-
News articles
-
Textbooks
-
Journals
-
Transcribed documentaries
-
Transcribed news stories
-
Survey research
-
Poems
-
Essays
-
Research field notes
-
Social media
The step-by-step approach to qualitative relational content analysis.
How to conduct relational content analysis - abridged
To start, identify a research question and select a sample or samples of text for analysis. Reduce the text to key concepts and code for words or phrases that represent the concepts. Next, determine the type of analysis you will use to explore the relationships between concepts. Apply another round of coding to analyze the relationships. Then, use statistical analysis to explore the differences and similarities between concepts. Finally, tabulate the results for your write-up.
Three subcategories of relational content analysis
Prior to the general steps of relational content analysis, there are three subcategorical strategies to consider and understand.
-
Affect extraction: Used to evaluate the emotion of explicit concepts in a text. Researchers use this method to capture the emotional and psychological state of the speaker or writer of the text. Affect extraction is problematic as emotions often vary across populations and time.
-
Proximity analysis: Here, a relationship is placed between two explicit concepts that occur within a specified string of words—called a “window”. The window is of a predefined unit of analysis (e.g. a single sentence or paragraphs) that reduces large groups of text into analyzable units. The goal is to identify where concepts co-occur.
The following image exemplifies an 11-word “window” of analysis, which includes the five words that occur before and after the concept:
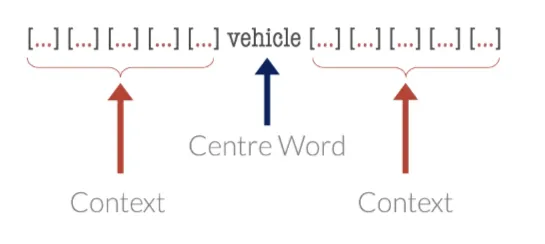
(Image)
Using this approach, concepts are organized into a “concept matrix”, or a “group of interrelated co-occurring concepts that might suggest an overall meaning.”[4]
-
Cognitive mapping: Researchers use cognitive mapping to further analyze and visualize affect extraction or proximity analysis. A cognitive map can depict a variety of different mental models—of the text, the writer/speaker, or the social group/period—according to the focus of the researcher. Mental models are representations of interrelated concepts that reflect conscious or subconscious perceptions of reality (Carley, 1990).
Basically, the map visualizes the way texts, people, or groups understand a concept. A goal of this process is to increase the reliability of results gleaned from affect extraction by allowing for comparisons to explore “how meanings and definitions shift across people and time” (Palmquist, Carley, & Dale, 1997).
There are no strict rules for creating cognitive maps. They are flexible and well-suited to examine wide sets of concepts. Some examples of cognitive maps include:
- Flowcharts (this example depicts qualitative content analysis itself)
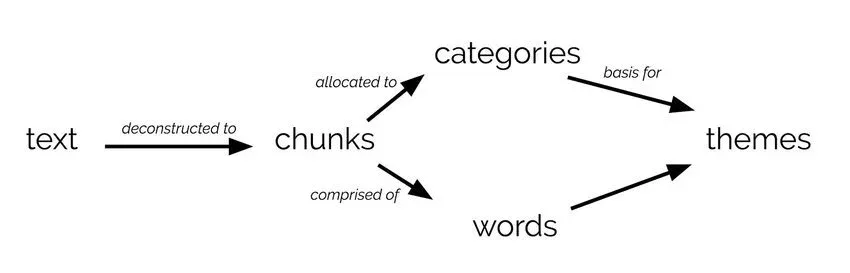
(Image)
- Concept matrix
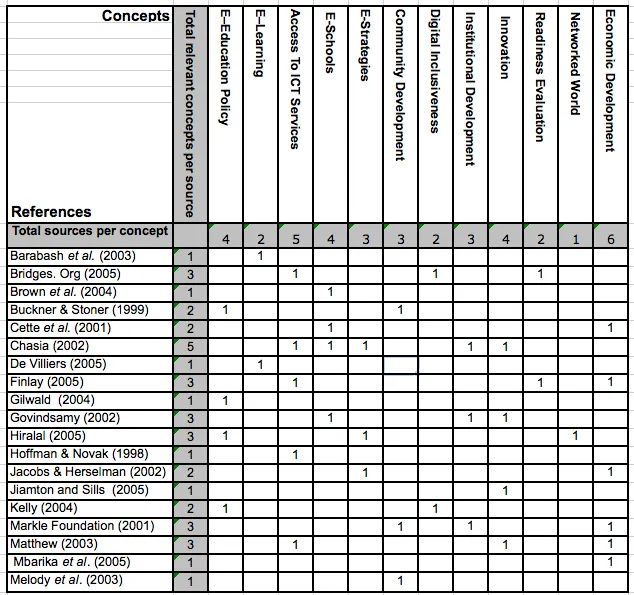
(Image)
- Word clouds (concept frequency represented proportionally)

(Image)
- Co-occurrence network (represented by proportion and relation)
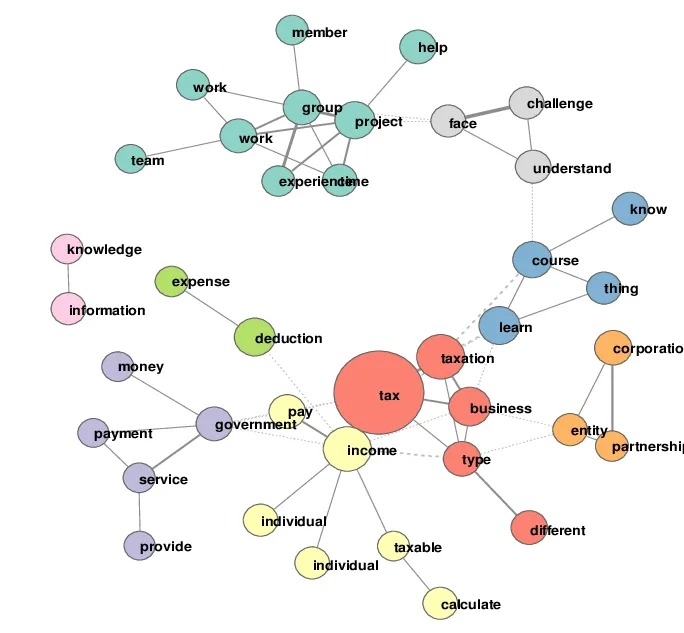
(Image)
It is important to note that these are only a few of the general options for visualizing data through cognitive mapping and the examples are not only specific to relational content analysis.
Steps to conduct qualitative relational content analysis - unabridged
Identify the research question.
Choose a research question to establish where your research is headed—and why. The focus of the research question prevents unlimited avenues of interpretation and infinite possibilities for concepts. Without structuring the process with a research question, analysis is very hard to complete.
To clarify, we will use a hypothetical study of Joe Biden’s campaign speeches that focused on healthcare during the 2020 US election race. The question researchers seek to answer is “What concrete information did Joe Biden’s speeches offer to the public in regard to US healthcare?”
-
Choose textual samples for analysis.
When choosing your samples, ensure you have enough information for a rigorous analysis that is manageable but not too extensive. If you use too few samples the analysis will be limited. Too many, and you risk overcomplicating the coding process to the point that you can’t offer effectual results or a clear conclusion.
In our hypothetical study, researchers chose five speeches. If they had decided to use a conceptual method of content analysis, more speeches may have been selected. But because researchers want to evaluate deeper relationships between concepts, which takes more time, a relational approach was used instead.
-
Determine the type of analysis.
Choose from the three subcategories above. In our example, the researchers decided to use a proximity analysis because it’s concerned with the co-occurrence of concepts. A cognitive map of the concepts was also provided in the final write-up.
Now, with questions established and text samples selected, the researcher needs to determine what types of relationships to explore—and the level of analysis to include: word, word sense, phrase, or sentence.
-
Reduce the text to categories and code for words or patterns.
By identifying concepts through proximity analysis, researchers create a concept matrix of interrelated, co-occurring words that might connote an overarching meaning.
In our example, researchers code for how often Joe Biden used words that were unclear, held double meanings or left an opening for a re-evaluation of meaning. Similarly, the researchers might also code for context words that are so ambiguous in nature that they obfuscate the importance of the information directly related to those words. Examples of such words could be “perhaps”, “barely”, or “sometimes.
-
Explore the relationship between concepts.
Once the words are coded, the text can be analyzed by several distinctions:
-
Strength of relationship: To what degree are two or more concepts related? These types of relationships are the easiest to identify and analyze when all the relationships between concepts are considered to be equal. Assigning strength helps retain a higher degree of detail from the original text and helps to decide whether words like sometimes or perhaps relate to a particular idea in the text.
-
Sign of relationship: Do concepts positively or negatively relate to one another? Signs signify whether there are positive or negative relationships between concepts. For example, the concept “bear” signifies a negative relation to the concept “stock market”. Likewise, the concept “bull” is positively related. Thus “it’s a bull market” could be coded to show a positive relationship between “bull” and “market”.
-
Direction of relationship: What types of relationships do the categories display? The directional approach focuses on the type of relationship categories exhibit. Coding based on direction can be useful in defining, for example, the impact of new information within a specific decision-making process. For example: “A implies B” or “A occurs prior to B” or “when A then B occurs”.
In our example, researchers note that “perhaps implies doubt,” “just about occurs before statements of clarification,” and “if sometimes appears, then there is room for Biden to change his stance on a specific healthcare issue.”
-
-
Code the relationships.
This step is a prime example of the difference between conceptual and relational analysis because in relational analysis the relationships between concepts are coded—not just the concepts themselves.
In our example, researchers take special care when assigning value to the relationships in order to determine whether the ambiguous words in Joe Biden’s speech are inconsequential fillers, or hold relevant information about the statements he is making.
-
Apply statistical analysis.
This step involves conducting statistical analyses of the data you’ve coded during your relational analysis. This often involves looking for differences or looking for relationships among the variables you’ve identified in your study. This step prepares the data used for the final step of relational content analysis.
-
Map out representations.
Generally, researchers create cognitive maps in order to analyze and depict mental models discovered during analysis. Using the statistical analysis from the previous step, researchers create visual representations of the concepts and their relationships across all textual sources in some kind of graphical display——e.g. cognitive maps.
The best CAQDAS software for relational content analysis
The best software for relational content analysis is the Delve qualitative analysis tool.
How Delve works
After identifying your coding framework of choice, you can prepare your data and translate that framework into a Delve codebook. You can then easily import text files into Delve, and use intuitive coding features to apply your codebook to the text. The software is fully cloud-based and the convenient auto-save feature ensures your work—and time—is never lost.
Advanced coding options for frequency counts
With Delve, frequency counts are automated by default. The software also provides advanced code frequency through code co-occurrence matrices. As mentioned, the matrices visualize how frequently codes overlap, and how your codes correlate to descriptors or attributes.
What is Delve CAQDAS software?
Delve is a collaborative coding software with no steep learning curve! It includes free tutorial videos, responsive customer support, an easy-to-use interface, and a cloud-based, Google Docs-style automatic save feature. All at a student-friendly price with flexible payment options.
Check out why researchers like Kieran and so many others are switching to Delve.
“Delve is incredibly easy to use, which makes it great for projects with multiple people working on them. There’s no learning curve or lengthy onboarding process.”
References
-
“Content Analysis.” The WAC Clearinghouse, https://wac.colostate.edu/repository/writing/.
-
Carley, Kathleen. “Coding Choices for Textual Analysis: A Comparison of Content Analysis and Map Analysis.” Sociological Methodology 23 (1993): 75–126.
-
Krippendorff, K. (2004). Content Analysis: An Introduction to Its Methodology (2nd ed.). Thousand Oaks, CA: Sage. Organizational Research Methods, 13(2), 392–394.
-
Content Analysis. (n.d.). https://www.publichealth.columbia.edu/research/population-health-methods/content-analysis.
-
Neuendorf, K. A. (2002). The Content Analysis Guidebook. Thousand Oaks, CA: Sage Publications.
-
Neuendorf, K. A. (2002). The Content Analysis Guidebook. Thousand Oaks, CA: Sage Publications.
-
Berg, B.L. (2001) Qualitative Research, Message for the Social Sciences. 4th Edition, Allin and Bacon, Boston, 15-35.
-
Palmquist, M. E., Carley, K.M., and Dale, T.A. (1997). Two applications of automated text analysis: Analyzing literary and non-literary texts. In C. Roberts (Ed.), Text Analysis for the Social Sciences: Methods for Drawing Statistical Inferences from Texts and Transcripts. Hillsdale, NJ: Lawrence Erlbaum Associates.
-
Carley, K. (1990). Content analysis. In R.E. Asher (Ed.), The Encyclopedia of Language and Linguistics. Edinburgh: Pergamon Press.
Cite this blog post:
Delve, Ho, L., & Limpaecher, A. (2023c, January 25). What is Relational Content Analysis in Qualitative Research? A Step-By-Step Guide https://delvetool.com/blog/relational-content-analysis