
This is part of our Essential Guide to Coding Qualitative Data | Start a Free Trial of Delve | Take Our Free Online Qualitative Data Analysis Course
Collaborative qualitative research is all about teamwork between researchers. It’s where you work with other researchers and turn the journey of qualitative analysis into a more interactive and insightful experience.
This article walks you through what collaborative qualitative analysis looks like in practice, from the shared task of coding to the real-world benefits of this team-oriented approach. And also what tools to help streamline the process.
This article will help:
- Learn best practices for collaborative qualitative research.
- Learn how to use online qualitative coding software for collaborative qualitative researc.
- Understand what to look for when choosing a qualitative coding tool for collaboration.
What is collaborative qualitative research?
Collaborative qualitative research is where researchers team up to dive deep into understanding experiences, beliefs, or social processes. This method emphasizes partnership, sharing insights, and mutual learning, moving beyond traditional researcher-subject dynamics. It’s about co-creating knowledge, where everyone’s voice matters, leading to richer, more nuanced findings. In essence, it’s research with people, not just about them.

When conducting collaborative qualitative research, it can be difficult to juggle each researcher’s contributions while building toward a shared analysis. Online qualitative coding software helps manage each person’s unique observations about the data while keeping an aligned codebook.
As mentioned, this article will show how to balance the tension between unique perspectives and group consensus while covering key topics in collaborative qualitative research, such as peer debriefing, researcher triangulation, intercoder reliability, split coding, consensus coding, and member checking.
How online software supports collaboration
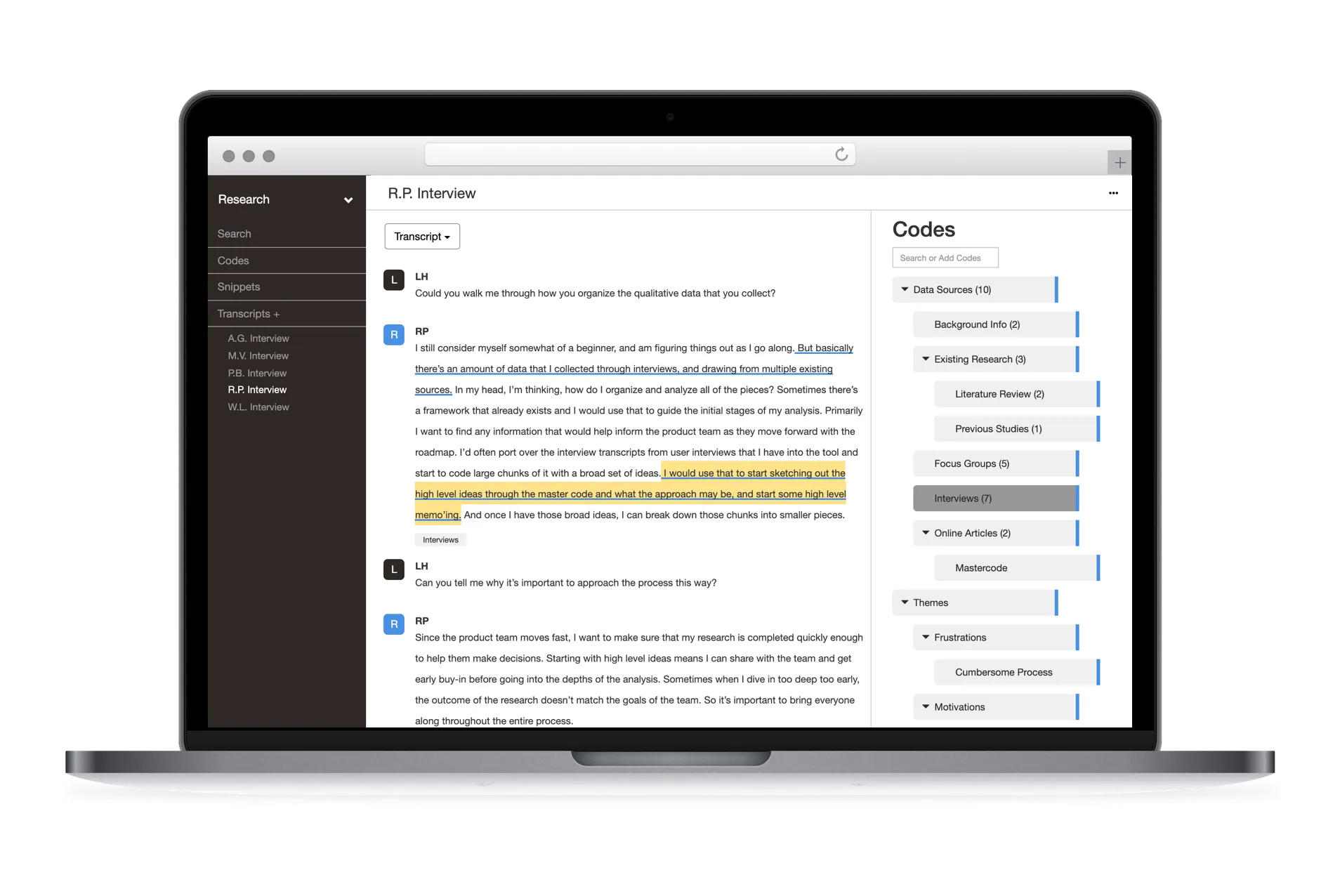
Delve, an online qualitative coding software.
Online qualitative coding software, often referred to as computer-assisted qualitative data analysis software (CAQDAS), helps analyze, categorize, and interpret large amounts of qualitative data. Transcripts from one-on-one interviews are just one example of possible data formats.
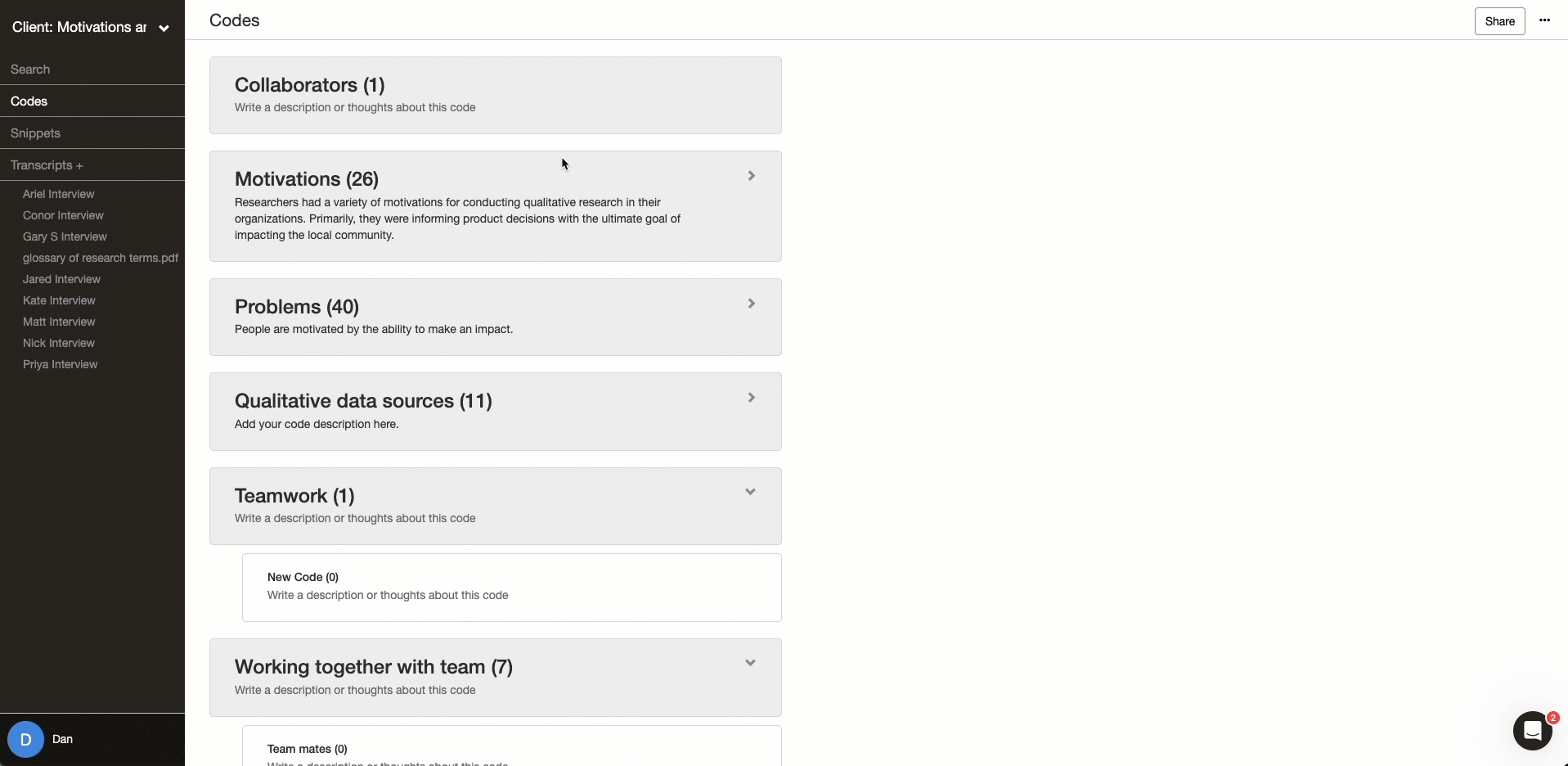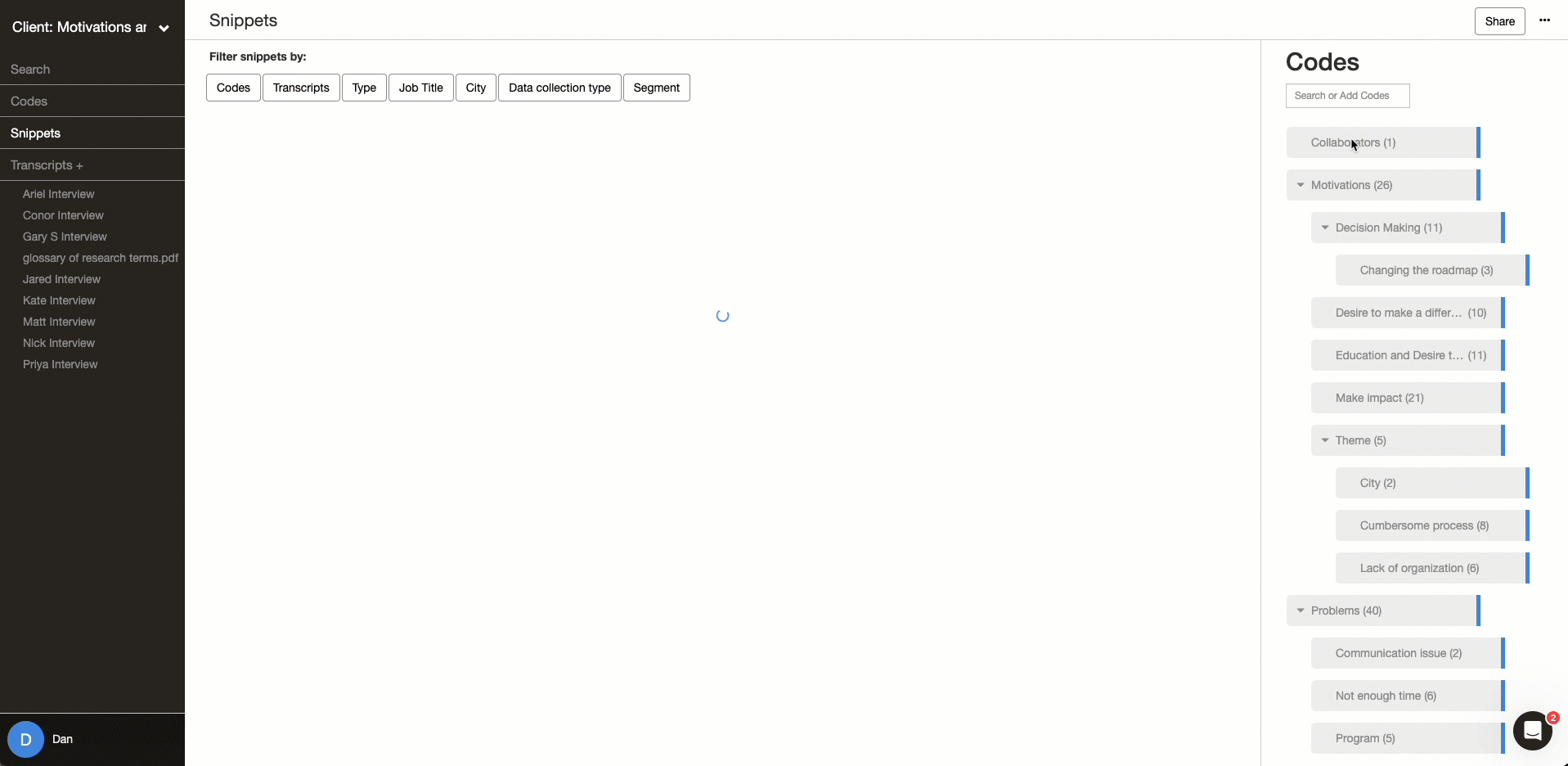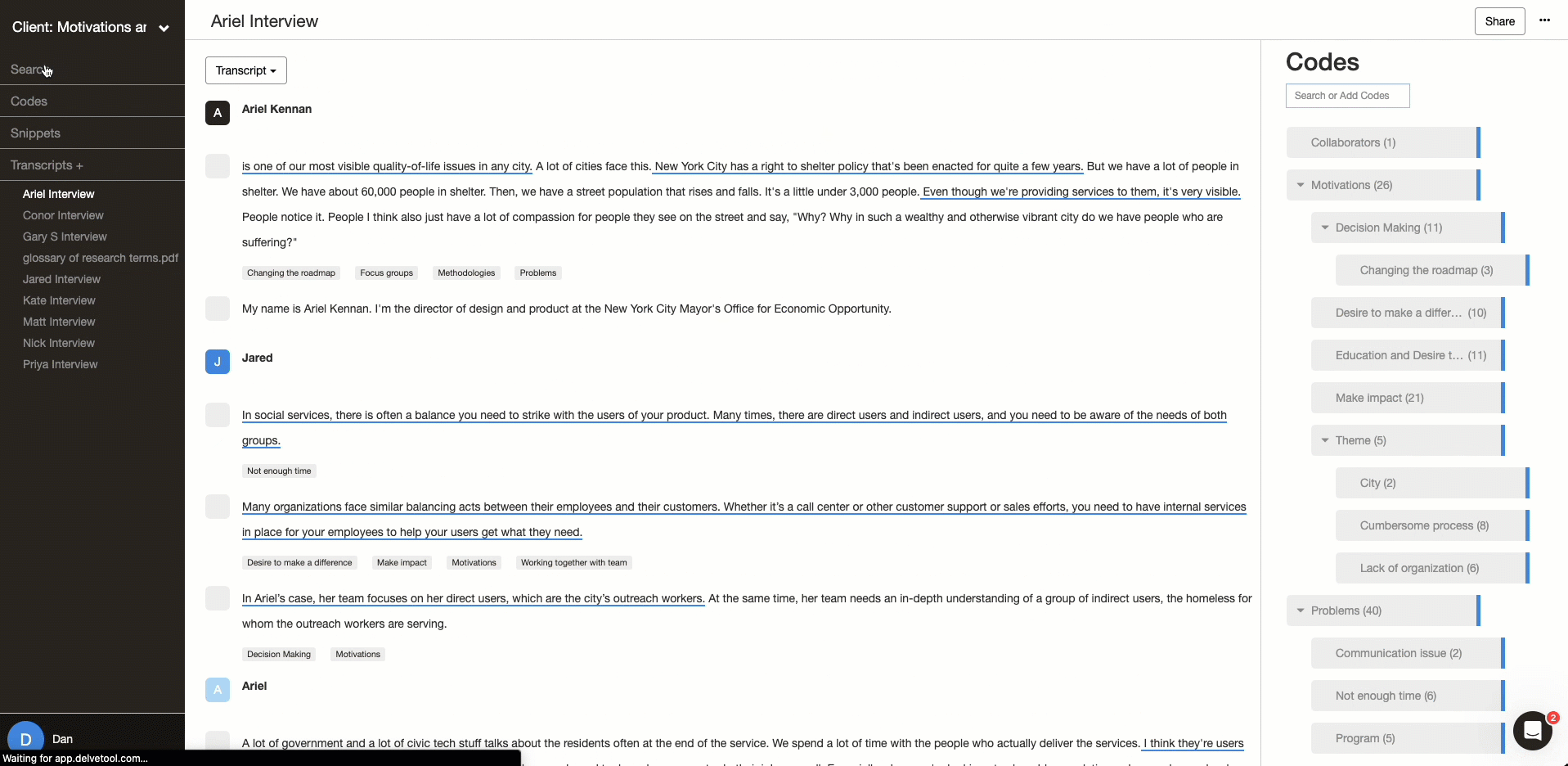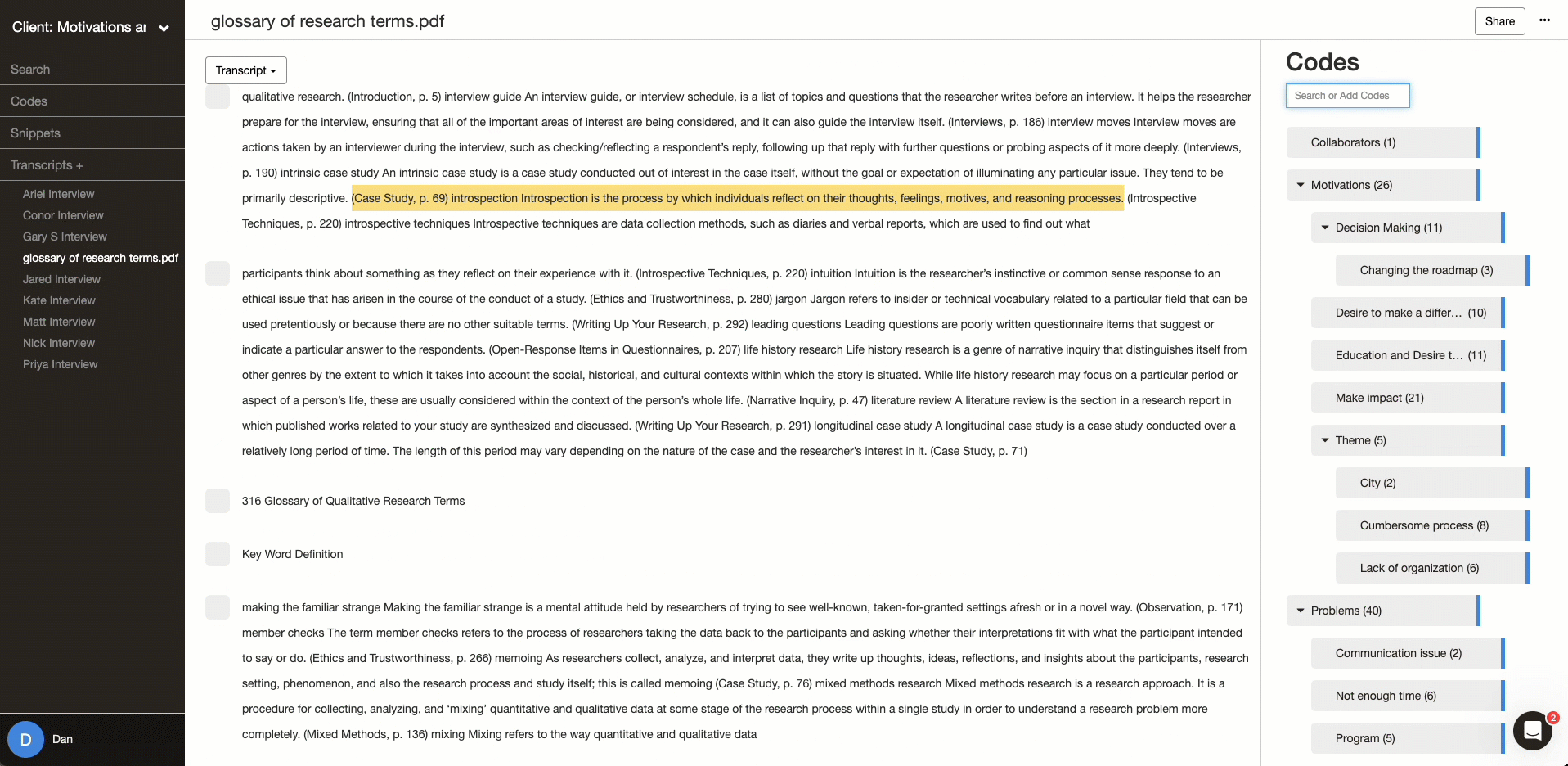
A key feature in qualitative coding software is the code. A code is essentially a tag that represents an idea, concept, or pattern that you use to label a section of your qualitative data. Good qualitative coding software will allow you to quickly retrieve all data you labeled with a code, so it can be further analyzed.
Each qualitative coding project will be made up of a number of different codes. As you work through your project, these codes will be created, rearranged, grouped, expanded, and merged until you have a well-organized “codebook.”
A codebook is a reference guide that defines and categorizes your codes. A well-organized codebook is the main output of qualitative data analysis. With every code having a concise name and detailed code description, it allows anyone, including yourself, to explore the richness of your data through the lens of your analysis.
Online qualitative coding software takes this same analysis process through coding and allows you to do it from anywhere, with anyone, at any time.
Online qualitative coding software takes this same analysis process through coding and allows you to do it from anywhere, with anyone, at any time. This increased flexibility is ideal for the modern trend of remote work in qualitative research.
To learn more about qualitative coding, please reference our Definitive Guide to Qualitative Coding. The rest of this article will focus on how to use online qualitative coding software as a group.
How Does Online Qualitative Data Analysis Software Help with Collaboration?

One of the key struggles of collaborative qualitative analysis is managing each person’s unique perspective on the data while also aligning on a shared understanding of it.
Online software for qualitative data analysis simplifies the organization and differentiation of each team member’s coding, letting everyone compare and gradually align on a shared codebook.
Here are three more ways that online qualitative software helps facilitate collaborative qualitative coding.
1. Makes researcher triangulation easier by enabling multiple people to be on a project
Researcher triangulation involves multiple researchers interpreting the same data set to verify their analytical results. However, the process can be particularly challenging if your team members are in different locations.
Online coding software lets researchers view, analyze, and compare data in real-time, regardless of their location. This streamlines researcher triangulation, especially for those working remotely.
2. Enables peer debriefing and member checks by enabling others to view your data
Qualified peers offer guidance through peer debriefing to enhance the validity of your research. They provide critiques on data collection, analysis, coding, and memos, contributing to the robustness of your project.
Online qualitative data analysis software streamlines the peer debrieing process. You can share your project with full access if you want your peers to code alongside you, or share your project with limited access if you just want them to view and comment on your data.
There are various points in your research where you may want a peer to see your process: after creating codes, making themes, and/or writing your research narrative. In all these cases, online coding software makes it easy to share your project with peer debriefers.
The software also streamlines member checks. Member checking, also called respondent validation, is where researchers and study respondents collaborate to ensure data accuracy. The technique is used to help verify qualitative data gathered from interviews, semi-structured interviews, or focus groups.
Coding tools make it easy to allow or revoke access by email address so that you can give data back to respondents to cross-check the accuracy of your initial transcripts or data analysis.
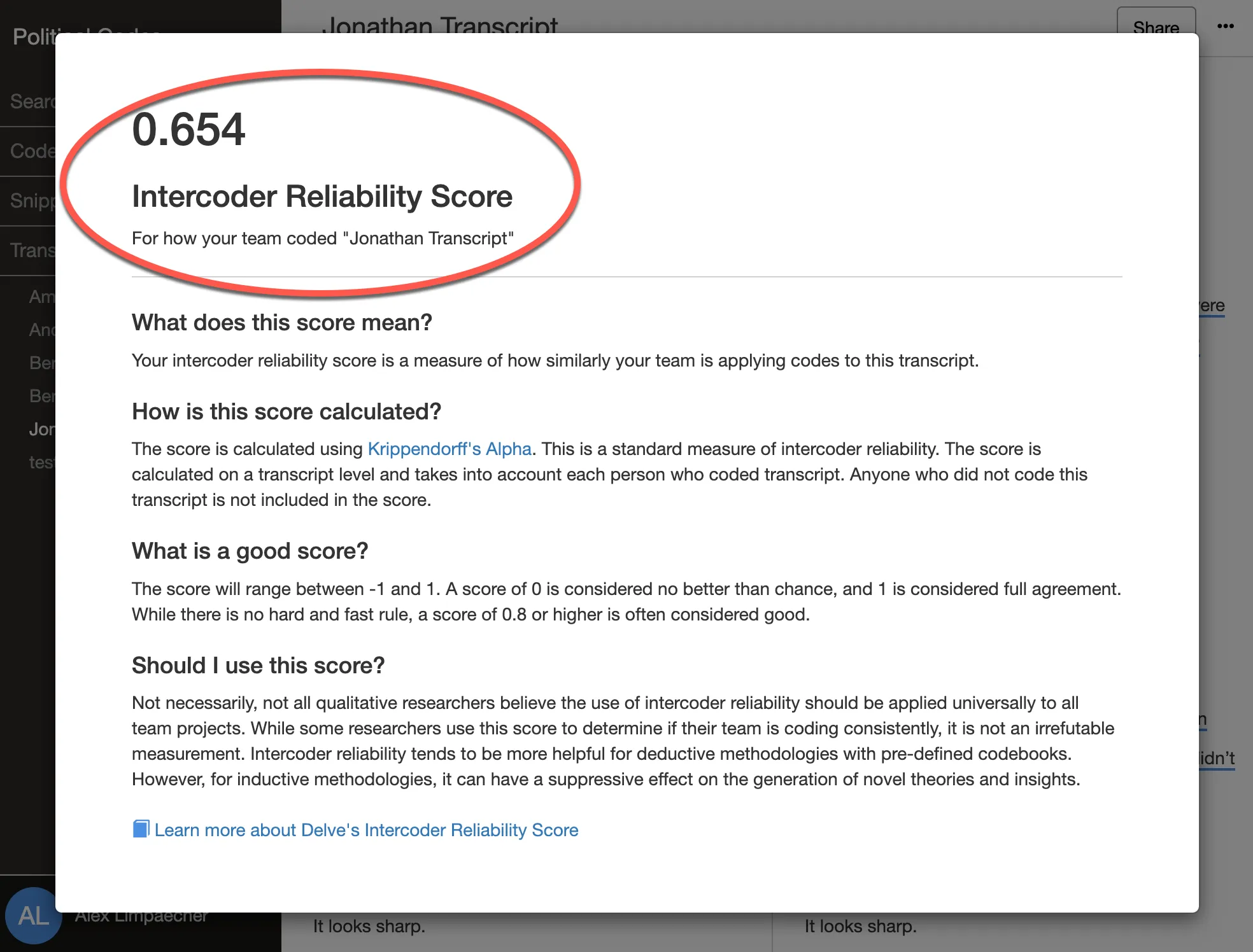
3. Helps calculate intercoder reliability efficiently
Intercoder reliability measures the agreement among co-researchers when applying the same codebook to the data. It calculates a numeric score that conveys how likely the team is to achieve consistent coding results. Intercoder reliability has three core benefits:
- Some journals may request intercoder reliability details as a form of evidence to demonstrate the reliability of your qualitative research paper.
- You can use intercoder reliability as a training tool for your research team to check that everyone is applying the codebook in more or less the same way. It is also helpful for training novice researchers.
- Once you are confident that your team is applying the codebook consistently, you can divide and conquer a large corpus of data by having each team member code different documents.
Online coding software supports intercoder reliability by allowing one project to be shared among multiple researchers. Each researcher codes independently and compares their coding. The software calculates the reliability score automatically, saving time compared to manual calculations.
Below, we’ll go into detail on how to use intercoder reliability as part of deductive qualitative coding.
Step-by-step guides for collaborative coding
How to do peer debriefing

1. Align your goals for peer debriefing
Communicate with your peer debriefers what your goals are. Be upfront about what type of feedback you’re looking for and what your expectations are. Discuss time commitment and deadline expectations for their initial feedback.
2. Share your project
When you’re ready for feedback, share your project with your peer debriefer(s). This can happen at any phase of the project, whether it’s during the planning session of your research, midway through coding, or after your final round of coding.
Depending on how immersive you want their debriefing to be, you can use a coding tool like Delve to specify if each peer debriefer has “View Only” or “Edit” access to your project.
- “View Only” is appropriate if you want your peer debriefer just to read your work and provide feedback without changing your codes.
- Grant “Edit” access if you want them to code sections of your data. This allows you to compare and contrast how you each applied your codes.
3. Ask for feedback
Ask your peer debriefers to leave feedback. You can receive feedback during a meeting or by leaving analytical memos within your project. With analytical memos, your peer debriefer can directly reference specific quotes, snippets, or codes.
Ask your peer debriefers to point out issues such as:
- Vague descriptions in the study
- Overemphasized or underemphasized points
- Bias assumptions or perspectives made by the researcher
- General errors or contradictions in the data, processes, or other parts of the study
- Lastly, it helps you become more aware of your views regarding the research
4. Compare how you coded
If your peer debriefer has time, ask them to code a small number of transcripts with you. This is a great exercise known as consensus coding.
By comparing your coding choices, using Delve features such as “Coding Comparison,” you can arrive at a deeper understanding of your data and your own subjective interpretation of it.
Coding comparisons aren’t about right or wrong coding. Differing codes from peers offer learning opportunities. And while similar coding doesn’t prove the validity of the code, it does instill confidence that you’re on the right track.
5. Thank your peer debriefers
Lastly, don’t forget to thank your peer debriefers for their time. Their contributions help enrich and enhance your research, providing new viewpoints that contribute to greater rigor. If professors or other peer debriefers aren’t available, you can also use AI as a peer debriefer.
Inductive and deductive group coding

Are you taking an inductive or deductive approach?
Before you begin group coding, consider whether you’re taking an inductive, deductive, or hybrid approach to coding. It is an important decision because the approach you choose will influence how your team codes your dataset.
Generally, inductive approaches are used for generating new ideas and theories. Whereas deductive is about applying an existing framework or evaluation to a dataset. While we will discuss the inductive and deductive approaches as if they are distinct approaches, mixing the two is common.
Deductive coding
With deductive coding, you start with a shared codebook and train your team to use it consistently. This is done in two phases.
- First, make sure that your team is coding in a consistent manner by coding the same transcripts.
- After you’re confident that the team has a shared understanding of your codebook, your team can divide and conquer by applying the codes to separate transcripts.
Intercoder reliability is a common way to confirm that your team is coding in a consistent manner. If the team deems the numeric score is not high enough, you have two options. The first is for everyone to align on your codebook by clarifying code definitions and discussing how each code should be applied.
Sometimes simply aligning your team is not enough, and an ambiguous or overly-complicated codebook could be the issue. In this case, you can iterate and refine your codebook until you’ve settled on one that your team can consistently apply.
After successfully training your team to consistently apply a shared codebook, the need for multiple coders coding the same transcript diminishes. Instead, split coding can be implemented, assigning different transcripts to each coder.
Inductive coding
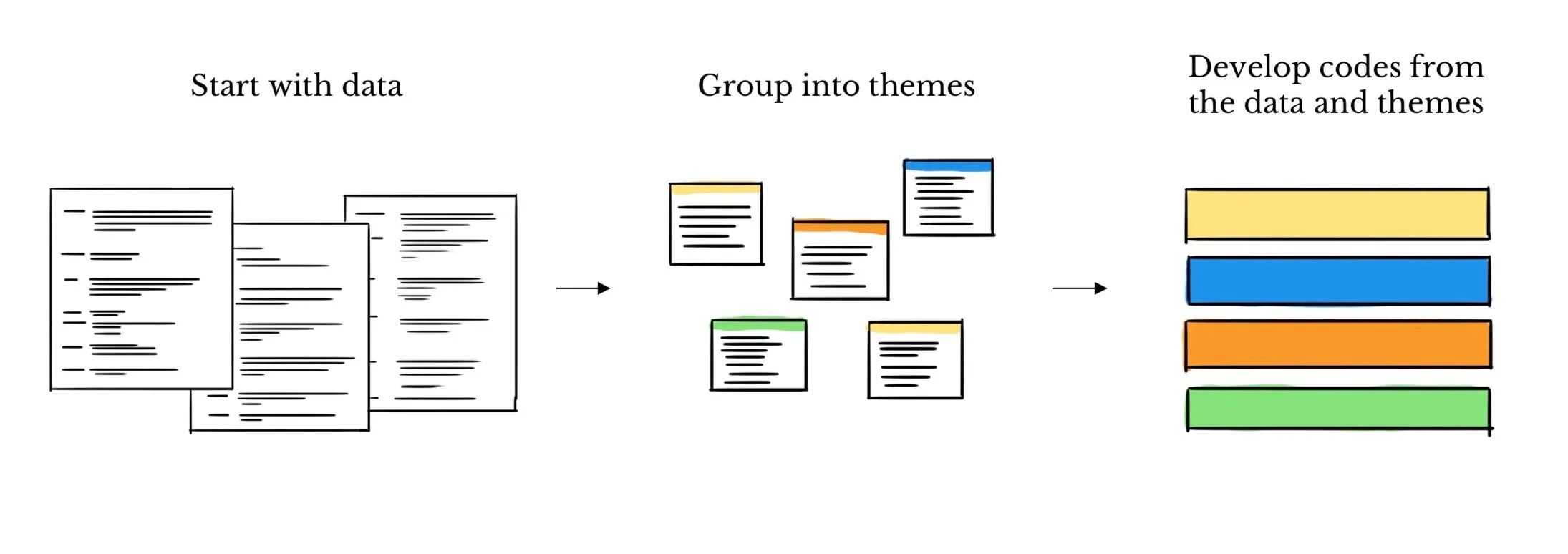
With inductive coding, your team builds a codebook separately and then iterates toward a shared codebook. Each member of your group will start by reviewing the data independently, deriving their own codes. Then, the team comes together to align on a shared codebook.
Each individual will maintain their own set of codes derived directly from the data while communicating regularly to align their thinking. After a number of coding and aligning iterations, the team creates a finalized shared codebook.
The team can then pilot-test this shared codebook through consensus coding, where they all code a handful of uncoded transcripts. If the team is satisfied with the codebook, they can analyze the rest of the transcripts with a combination of split coding and continued consensus coding.
Still not sure whether to use inductive or deductive coding?
Think about whether you’re looking for each person’s unique and diverse perspective or looking for each person to code consistently. Be clear on what you’re looking to achieve by working with a group.
Some teams are looking to encourage diverse perspectives and thinking, where you want each team member to bring in their own ideas and codes that others may not think of. Alternatively, you may want each person in a group to code similarly with one another so you can reliably use them to consistently code a dataset.
If you want diverse perspectives, an inductive approach may be better. If you want everyone to code consistently, a deductive approach may be better.
Using a deductive + inductive hybrid approach
You don’t necessarily have to choose either an inductive or deductive methodology. Often, groups will use both methods.
In abductive coding, for example, researchers start with a set of codes based on a theory or research questions and code deductively before adding more inductive codes based on the data. Likewise, a group of researchers may develop a codebook inductively and then work with research assistants to apply that codebook deductively to a larger dataset.
These approaches do not need to be kept strictly separate, so you are free to use a combination of both approaches.
Step-by-step guide to deductive group qualitative research
If you have a specific framework or evaluative method in mind, these steps can guide you in conducting deductive qualitative analysis with a group.
Keep in mind that these steps provide one example of how to do deductive group research. There are many other valid approaches but you can use this guide to organize your process.
Step 1. Communicate the research objective to your group.

Each member of your group should be informed about your research objective and goals. For example: Is your goal to publish a paper? To take action on the results? How rigorous do you need to be? What type of codebook will you start with – and why? Establish these objectives and goals ahead of time as a team.
Step 2. Establish everyone’s role and communicate expectations.
As a team, you should be clear on the role of each person on your team. Each person can also have multiple roles. Just make sure someone holds that role’s responsibilities. Here are some key roles to consider:
-
Research Lead(s) - The research lead is primarily responsible for developing a research design, setting predefined codes based on existing theories, and ensuring a systematic coding process. They also oversee data collection, manage the project team, verify data analysis, and contribute significantly to interpreting the results. Another core responsibility is to present the findings in an effective and meaningful manner.
-
Codebook Manager - The codebook manager holds the responsibility of maintaining and managing the codebook. Their role includes refining and updating the codebook as the analysis progresses, ensuring consistency in coding among different coders, and resolving any disagreements or ambiguities that arise in the coding process. The codebook manager may be one of the team leads, but not necessarily.
-
Contributor - A contributor is a team member who is actively using the codebook and applying codes to transcripts. They are responsible for understanding the definitions and nuances of each code, applying them consistently to relevant sections of the data, and engaging in discussions about potential ambiguities or disagreements in code application.
-
Peer Debriefer - A peer debriefer is a peer who plays a critical role in ensuring the credibility and validity of the research findings. They review and offer feedback on coding, interpretations, and conclusions, prompting the research team to explore alternative explanations and critically evaluate their approach and results. Peer debriefers’ insights help minimize bias and boost the study’s credibility.
The research lead should set up a regular method of communication. Will the group meet up on a weekly basis or check in via email daily? Communication is key in collaboration, so make sure expectations are clear from the start.
Step 3. Determine your reliability standard.
When conducting deductive analysis with a group, the group will want some level of consistency in how the codebook is applied. This level of consistency, however, can vary depending on your research goal.
For example, if your group is publishing in a journal, the journal may require an intercoder reliability score that exceeds a particular threshold. Alternatively, your group could be working on a school project where you use the reliability score simply as a quick way to know if you are coding consistently.
Depending on your goals, your level of rigor for getting consistent coding will change. The team lead should communicate this to everyone.
Step 4. Define the initial codebook.
Your team lead or codebook manager should create your initial codebook. The codebook could be based on a previous codebook, an existing theory, an evaluative framework, consultations with experts, a research hypothesis, or another source.
Each code should have a clear name and description. They should also be distinct from each other to remove potential ambiguity. Use online qualitative software like Delve to add your codes and code descriptions into a project that everyone can access. Delve’s Apply Codes with AI can also offer initial ideas to check or run your initial codebook across a transcript as a quick sanity check. This can be useful for spotting codes that are too broad or too similar before your team commits to them. The team still reviews every decision it makes.
The team should meet to discuss each code and its definition. Each team member should leave these meetings with a clear understanding of what each code is and how to apply it.
Depending on your specific approach, these codes may change as you test the codebook with your team. In some deductive research approaches, you don’t have the option to adjust the codebook. But in others, you may have leeway in evolving the codes as you analyze the data.
Step 5. Test the codebook with your group.
After your group understands the codes and their definitions, it’s time to test how your team applies the codes.
The code manager should upload the code and definitions into an online coding software and share the project with each team member. Each team member can now code the same transcripts using this codebook. Use a feature like “Coded by me” in Delve so each person only sees how they coded by hiding everyone else’s work. This ensures that no one influences how a contributor codes.
Step 6. Determine if you hit your reliability threshold.
After everyone has taken a pass at coding a number of transcripts, the team lead should check if you hit your reliability threshold by calculating the intercoder reliability score from step 2.
Did the group achieve the level of reliability and consensus that it was aiming for? If yes, skip ahead to step 8.
If not, don’t worry. It’s very rare for a group to hit the reliability threshold the first time. Step 7 addresses coding discrepancies.
Step 7. Revise the codebook and/or retrain if the reliability threshold isn’t met.
Don’t worry if your group didn’t hit the reliability threshold. Teams often have to go through multiple training sessions and iterations before they are coding consistently. This is normal and expected.
First, you need to understand what caused the intercoder reliability score to be lower than your threshold. The team lead or code manager should review and compare where the contributors coded similarly or differently. They can use a feature like “Coding Comparison” in Delve to compare two coders side by side.
As part of this evaluation, talk to your team in person or over memos about why they choose a particular code. Based on this comparison and discussion, you can diagnose why your group did not hit the reliability threshold. Keep in mind this could be for multiple reasons, including:
-
Codebook is unclear: Teams are often unclear or misaligned on a code’s definition. In this case, the code manager and team lead should clarify and refine the code description. In addition, they can provide example quotes in the code description to provide a concrete example.
-
Too many codes: When a codebook has too many codes, it can lead to scenarios where multiple codes could be considered valid. This can hurt your intercoder reliability score. In this case, you may want to reduce the number of codes by merging some together or deleting some that no longer serve your research. Online qualitative data analysis software like Delve makes it easy to iterate and evolve the codes and code definitions.
-
Overlapping codes: In deductive coding, it can be helpful for your codes to be clearly defined. If the code definitions overlap, you may need to reconsider how you are converting your theoretical framework into a codebook.
-
Group members need more training: Sometimes, group members need more training and practice with the codebook to understand how to effectively utilize it. Try having them code more transcripts but under the mentorship of more experienced members of the group.
💡They may also need some general training in how to do qualitative data analysis. We recommend everyone take Delve’s free online Qualitative Data Analysis Course for anyone that’s new to qualitative coding.
Oftentimes, your group will need to adjust the codebook, clarify the code definitions, and go through more training. Don’t sweat it. Just keep iterating and continue until the team has hit your reliability threshold. Once you have another codebook, test it again, starting with step 4.
Step 8. Split coding after hitting the reliability threshold
If you hit your reliability threshold, congratulations! Your team has effectively taken the shared codebook and coded to your reliability threshold. You can now rely on each team member to code consistently when splitting up and coding different transcripts (known as split coding).
At this point, the coding process should speed up since you don’t need multiple people to code the same transcript.
Step-by-step guide to inductive group qualitative research
An inductive approach to group qualitative research is beneficial for two main reasons: it allows for theory generation from your collected data, and it capitalizes on the distinct viewpoints of each team member. Here’s a step-by-step guide for inductive qualitative group coding.
Step 0. Communicate clearly your research objective to your group.
Before you begin, the research lead should inform the team of the project’s research objective and goals. Particularly with an inductive approach to coding, like collaborative thematic analysis, sharing an understanding of the research objective can help align your later analysis. The research lead should also discuss publication goals and the final authorship of any research publications.
Step 1. Establish everyone’s role and communicate expectations.
The primary difference between inductive and deductive coding is when codes are created and who creates them.
With deductive coding, codes are created and adjusted before rounds of analysis, most often by the team lead or codebook manager. On the other hand, inductive codes are created during the coding process by all of the coders.
This can make the analysis feel less structured and keep the emergent codebook changing constantly. Clearly defined roles and communication strategies help prevent these issues. Setting detailed permissions for proposing, modifying, including, or removing codes in your coding software also helps.
Note that the codebook manager is crucial in inductive group coding as any member can add new codes, making management more complex than in deductive group coding. The team should set clear rules for how or if the manager is allowed to adjust others’ codes.
With those decisions settled, share your project with each team member using the appropriate permission settings. If you use Delve, the project leader will own and share the project with other group members.
The research lead should also set up a process for regular communication. This will include how often the group will meet in person and what tools – such as email and online memos – you will use to communicate. If it wasn’t clear by now, communication is key in collaborative research.
Step 2. Determine your approach to coding
In inductive group coding, each team member will derive their own codes from the data. But it’s important to establish clear guidelines for your group’s approach. Try answering questions like:
- What methodology will you be using, such as grounded theory or thematic analysis?
- Do you expect to be using descriptive coding, open coding, and invivo coding?
- Roughly how many codes do you expect each person to add?
You don’t need to predefine everything; just keep communication open so that everyone is on the same page.
💡 If there are people on your team who are unfamiliar with coding, consider enrolling them in an online course on qualitative data analysis (Delve has a free online course) or do a pre-training round.
Step 3. Each person codes the same transcript independently


By this point, the team lead has created a project with transcripts in an online qualitative data analysis tool and shared the project with the rest of the team.
Now, each person codes the same transcripts independently. As they read through the transcripts, each researcher will add their codes based on their interpretation of the data and according to the group’s guidelines set up in step 2. By using a feature like Delve’s “Coded by Me” feature, each team member codes the data without any outside influence, giving more room for unique codes to emerge.
It’s good practice to leave notes in the code description of what each code represents. The researchers can also leave analytical memos to explain why they coded a snippet in a particular way – or just to mention patterns and themes they want to discuss as a team.
Step 4. Compare and discuss codes
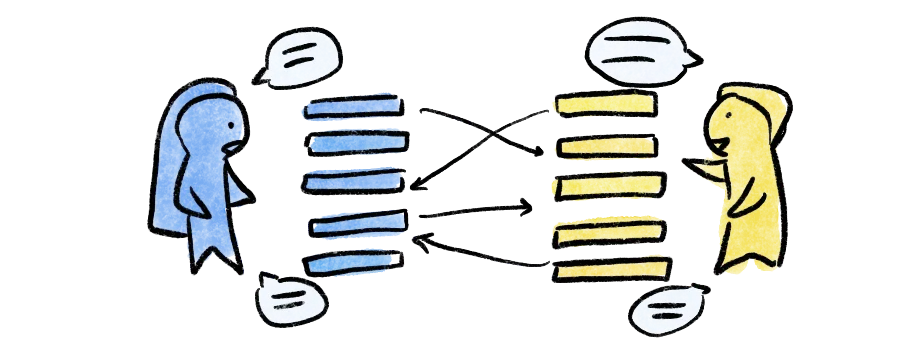
Once everyone’s coded the same transcript, meet as a group to compare how you coded.
The team should look at the transcript line by line in addition to discussing the codes created. A Delve feature like “Coding Comparison” allows you to see a side-by-side comparison view of how each person coded the same line. The team should discuss the similarities and differences in their codes. The goal is for each team member to feel like the core aspects of their analysis are understood by the rest of the team.
Alongside the side-by-side comparison, the group should also talk about overarching themes or patterns emerging from the analysis. This discussion can offer fresh perspectives and insights. Analytical memos written during the coding process can also lead these discussions.
Step 5. Align on codebook
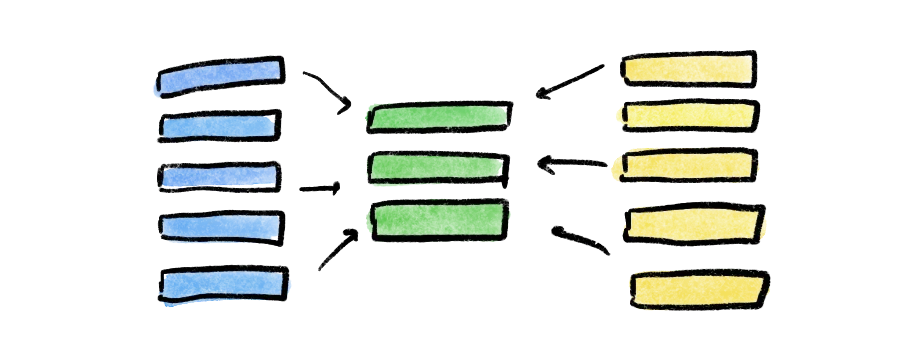
Based on these conversations from Step 4, you can begin to consolidate or merge codes.
For example, one person may have created a code called “Working with a Team,” while another created a different code called “Group Dynamics.” The group should evaluate if the two codes are referencing the same thing by comparing how each coder applied them to the transcript.
The group may decide to merge these codes together. Alternatively, if there are clear differences in how they were applied, the group may want to refine the code name and description to differentiate them. Delve’s qualitative data analysis software makes it easy to merge, edit, rename, and delete codes, which automatically updates the project for all team members.
Remove codes that no longer serve your research or fit within your research goals. Your code should encompass various viewpoints, reflecting each team member’s perspective. Engage in discussions to understand differing interpretations of the data and incorporate each member’s insights into the codebook.
Lastly, don’t worry about perfectly aligning your codebook during your first meeting. The team will code multiple rounds of transcripts and iterate on the codebooks numerous times. With each round, the team will generally find itself aligned on more and more codes.
⚠️ Remember that coding is seldom a straightforward journey, especially in a group setting. Plan for multiple iterative rounds, as outlined in step 6.
Step 6: Repeat Steps 3, 4, and 5. Continue coding with an updated codebook
Now that the team has aligned on some codes, return to step 3.
Have each coder take another pass at applying those initial codes to another set of transcripts. Everyone will still be developing their own codebook as they apply group codes and individual codes to transcripts.
With each iteration of coding, discussing, and aligning, the team will have a growing understanding of the patterns and themes in the data. At a certain point, the team will agree that they have reached alignment on the key themes and patterns that you see in the data, and at that point, you can move to step 6.
According to Hemphill & Richards (2018), this alignment tends to occur after coding 30% of your transcripts. It can be sooner for larger datasets. We find this to be a useful rule of thumb to follow when conducting group analysis.
⚠️ Don’t expect to have a perfectly aligned codebook at this point. With so many people contributing their own codes, your codebook can feel messy. You will know that you have finalized the codebook when the group is not finding fundamentally new patterns or themes.
Next, the team will solidify a finalized codebook that represents each team member’s unique insights.
Step 7: Finalize the codebook

Eventually, codes from each group member should be converging toward a single unified codebook. However, it’s common for the codebook to need some cleanup, even at this late stage.
While these edits can be done as a group, it can save time for one member of the team (often the codebook manager) to go through the codebook, make final edits, and ensure the code definitions are descriptive, clear, and concise.
Step 8: Pilot your finalized codebook with consensus coding
At this point, you should be fairly aligned as a team. However, it’s crucial to confirm that alignment.
First, meet as a team to discuss the finalized codebook. The codebook manager should explain the changes that they made and give everyone a chance to remark on the finalized codebook. It’s important that each member feel like their analysis has made it into their finalized codebook. Or to understand why it was left out. If anyone has any misgivings about the new codebook, discuss and address them.
Now with a finalized codebook, the team should pilot-test it by coding a couple of the same transcripts (consensus coding). Like with step 3, each coder should use the “Coded By Me” feature, so they can only view their own work. However, unlike step 3, at this point, no new codes should be added.
If team members feel like they are missing codes, they should make a note of it so they can discuss it as a team. It could be that the codebook manager may need to return to Step 6 and create an adjusted finalized codebook. If this is the case, don’t hesitate to pilot-test this new codebook.
Step 9: Divide up transcripts and code independently with split coding

Once your team is satisfied with the finalized codebook, the group no longer needs to have multiple people coding each transcript.
With the team aligned, use the finalized codebook to divide up transcripts and code independently with split coding. Your coding should move much faster now that you have an aligned codebook that you can apply to the rest of your data.
At this point, it should be rare to make major changes to the codebook, but it doesn’t mean it can’t happen. If new information arises that seems relevant to the group research objectives, any member should bring it up in a team meeting or note it in an analytical memo.
Once the group is done coding the remaining transcripts, it can use the codebook to begin writing the final analysis.
What to look for in a collaborative coding tool for qualitative analysis
Choosing the right collaborative coding tool for qualitative analysis can be daunting. With varying functionality and features, not all options are suited to your team’s needs. Here are some factors to help you make an informed decision about the best online coding software for your research team.
Live updates with no need to merge files
Web-based software for qualitative data analysis enables you to see live updates of a project. As soon as someone adds a new code, you will see that code in your own project, making it much simpler to ensure that you’re coding with the same data set.
Alternatively, desktop-based tools require you to constantly share and sync files which add logistical overhead and risk team members wasting time by accidentally using an outdated version of the codebook. Desktop-based tools will often require you to merge projects, which takes time and can often lead to unsalvageable merge errors.
Mac and PC compatibility
Desktop qualitative software often has different Mac and PC software versions. Often these different versions will not have the same exact functionality. To make matters worse, sharing between the two versions can be difficult, which can cause particular problems for collaboration when your team doesn’t have the exact same type of computer. At worse, compatibility issues can lead to data corruption which can waste precious time or even loss of valuable data.
Using online software for qualitative data analysis avoids all these issues by providing the same software experience to every team member regardless of whether they are using a Mac or PC (or even Linux!). Online software is browser-based, so it works the same for everybody, making it the easiest way to work with a group.
Web-based, free software updates
It’s important for each member of the team to use the same version of the software. Otherwise, your project may be stuck between multiple versions.
Desktop-based tools, such as NVivo and MAXQDA, are constantly creating new versions of their software. These versions are rarely “backward and forward compatible,” which means if you create a file in one version, you (or a team member) will not be able to open it with another version. This would perhaps be okay if these version upgrades were provided for free. However, the business model of desktop-based qualitative tools is to charge you for these upgrades.
With web-based software like Delve, you always have the latest version, ensuring that every team member automatically gets the most up-to-date version of the software. You don’t need to track and worry about what version you have because it is all managed for you behind the scenes. Collaboration, in this case, is seamless, as every researcher will always have the exact same version of the software and data.
Easy to learn, easy to code
Most research groups have a variety of different skill levels. When working as a group, you want to be focused on conducting your research and not getting more novice researchers up to speed on difficult-to-use software. That’s why using accessible, easy-to-use qualitative coding software is essential to getting your research done well and on time.
You’ll also want a tool that has readily available onboarding guides and up-to-date support articles so everyone can get up to speed quickly
Customer support
Responsive customer support. Different people on your team may have different levels of familiarity with the tool. Having a dedicated support team made up of knowledgeable researchers helps everybody get familiar with the software, which can be a tremendous help to your team.
Collaboration Features: Add Memos, Compare Work, and More
There are a number of essential features that you need if you want to collaborate as a group. These include project sharing, memoing, a shared codebook and code descriptions, the ability to view or hide other people’s codes, the ability to compare two people’s work, and (if you need it) intercoder reliability.
We will go into more detail about each of these features below.
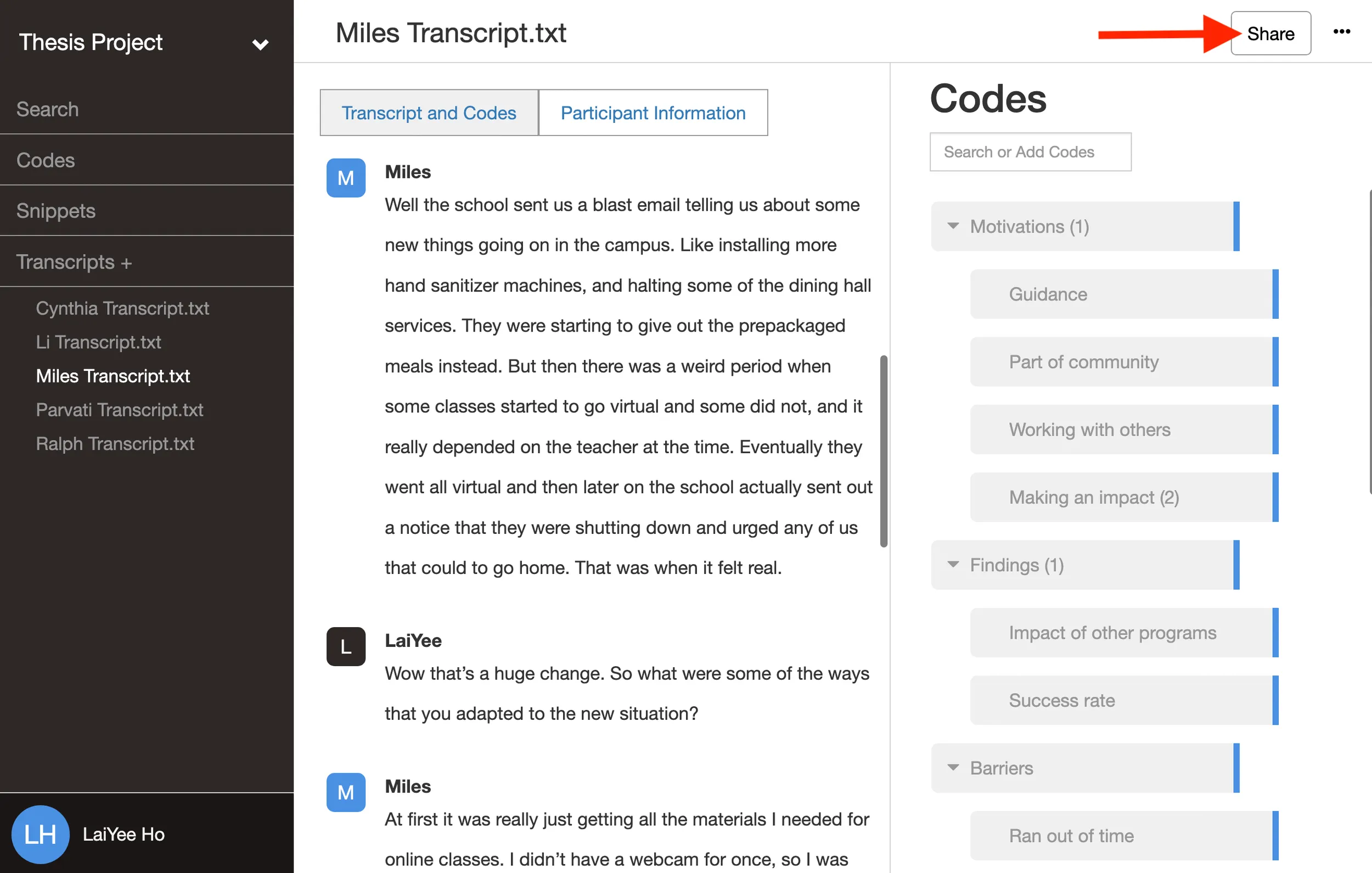
The ability to share a project with your collaborators, coders, or peer debriefers
Having an online tool that automatically syncs your work with your collaborators makes group qualitative analysis easier. Online software automatically updates for everyone each time someone adds a transcript, applies a code, or edits a description. Some desktop tools can merge two separate project files. However, this can still lead to merge conflicts, software version incompatibility, and a lot of overhead work. We highly recommend an online tool instead of a desktop-based tool.
In online qualitative data analysis software like Delve, you can share your project using the share button on the upper right-hand side of the screen. Everyone’s changes will immediately be available to everyone else.
Ability to add code descriptions to align on codes
Code descriptions are how your group will communicate what a code is and how it will be used. Also, your code descriptions are commonly reviewed by peer debriefers and instructors when taking a look at your research. Find an online qualitative data analysis tool that has an easy way to add code descriptions and update the changes live to all group members.
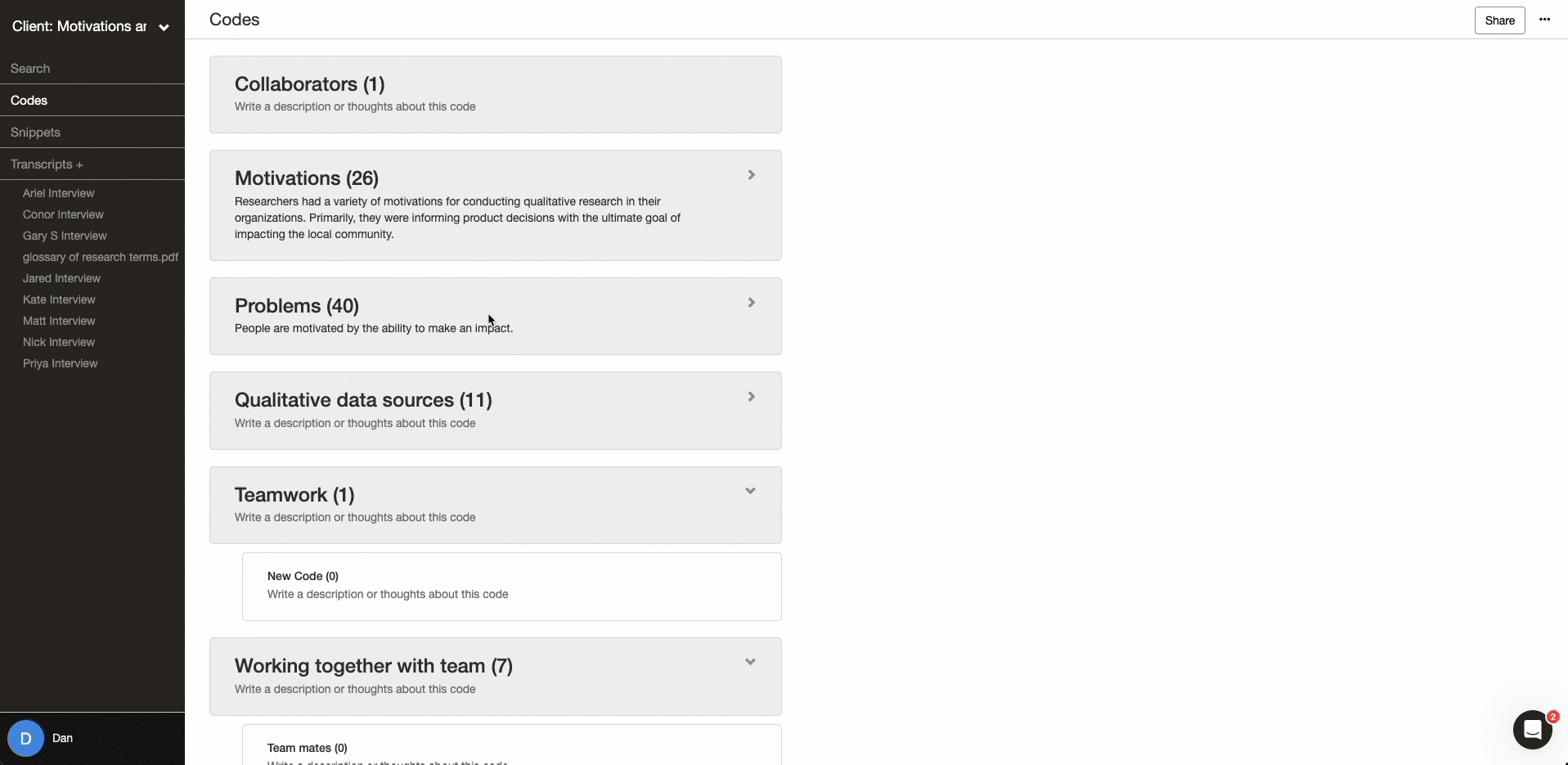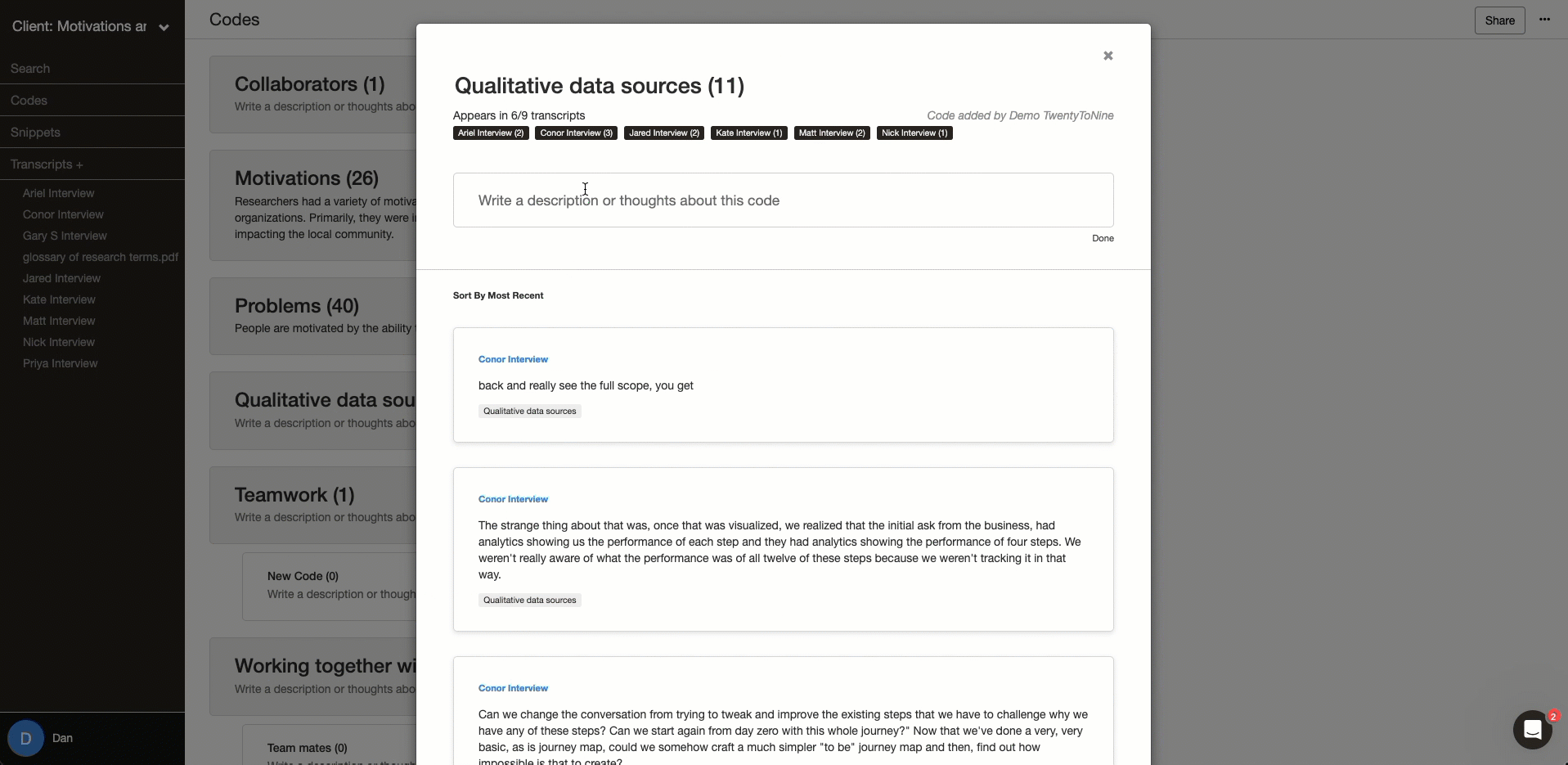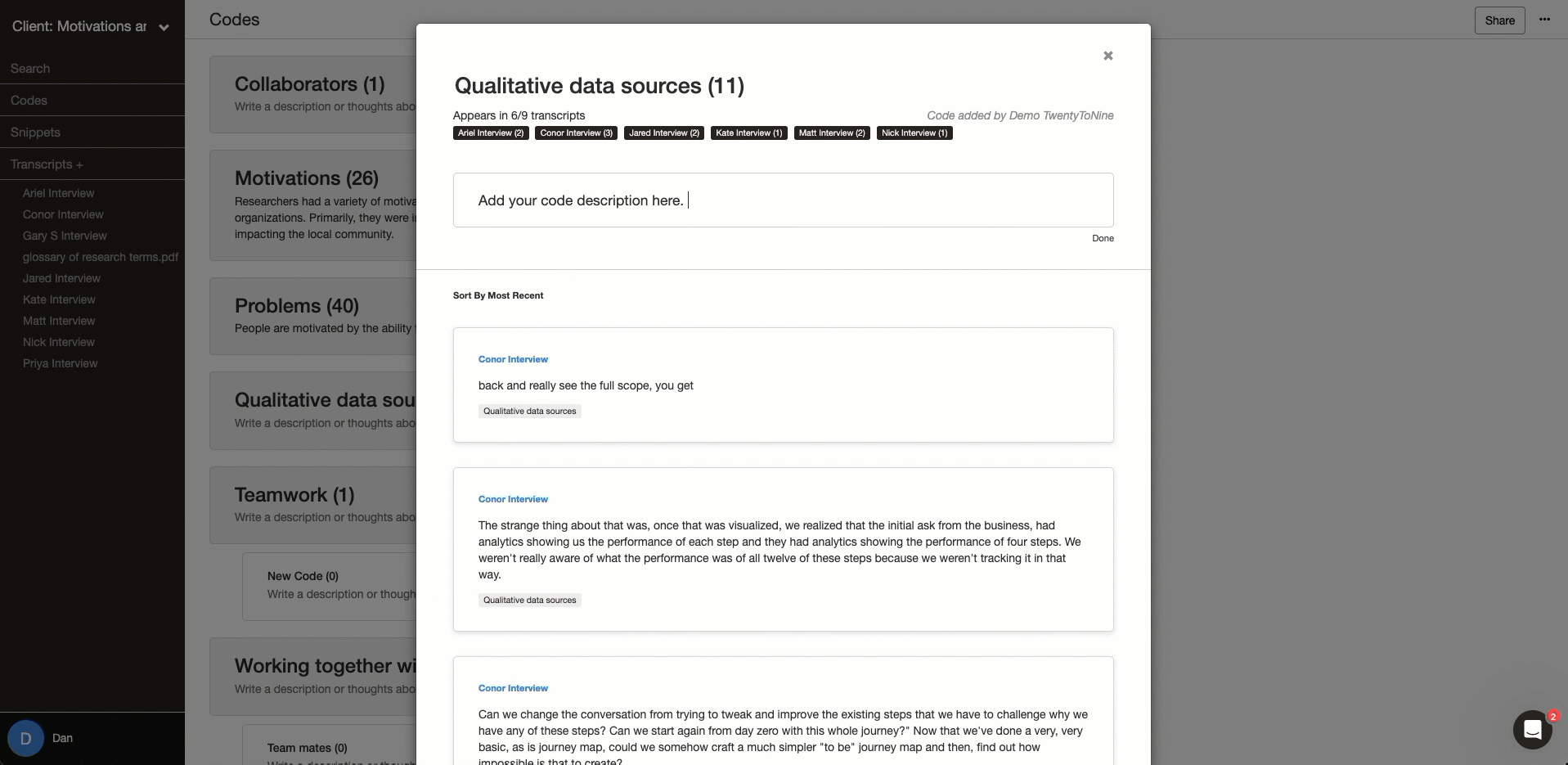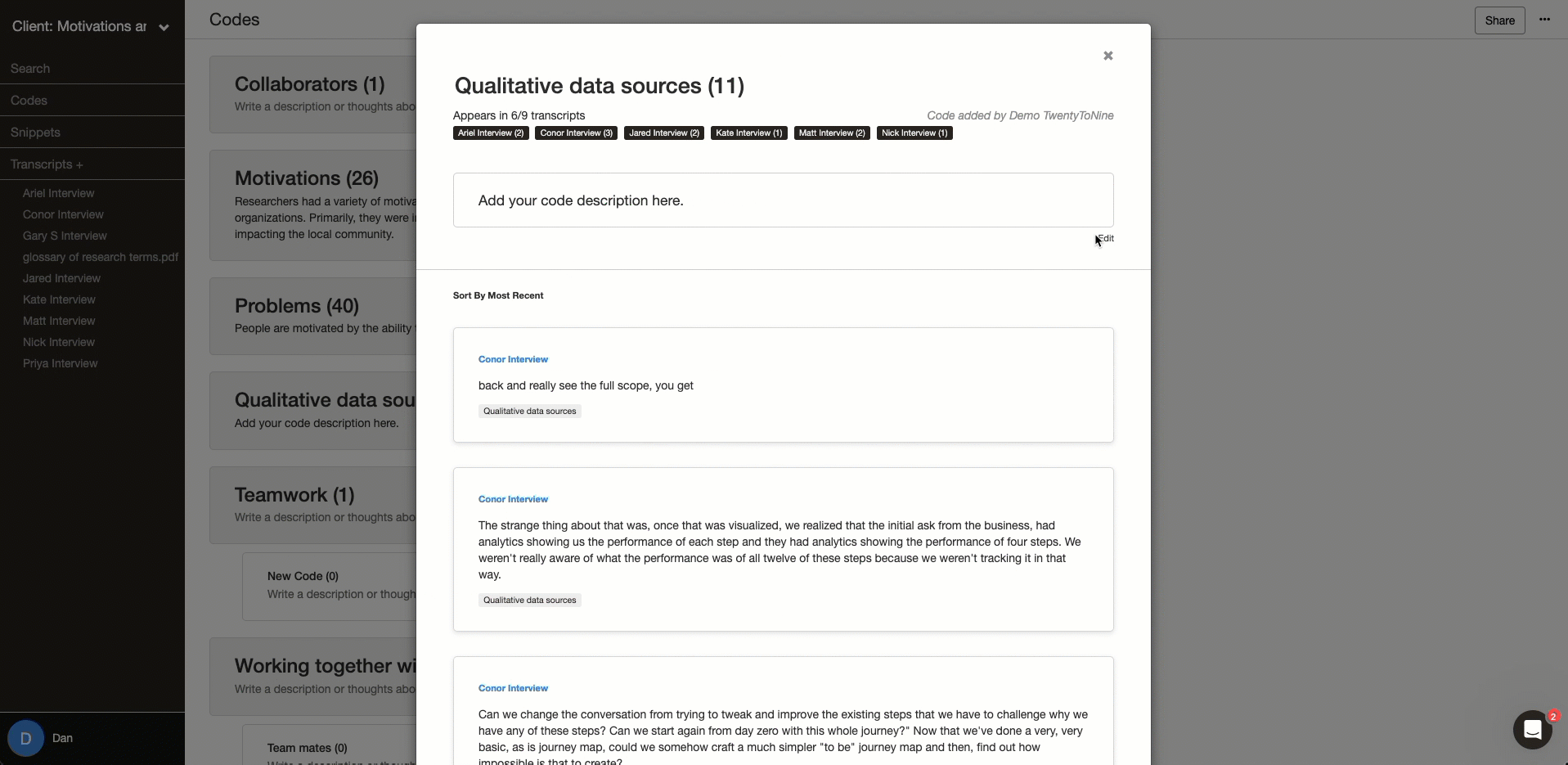
Analytical memos for discussions
Memos are an essential way to communicate regardless of what style of collaboration you are doing. It can help you discuss differences and align your coding. Memos are also key to capturing your reflexivity. Delve’s memo feature helps organize, centralize, and document the collaborative aspects of the project.
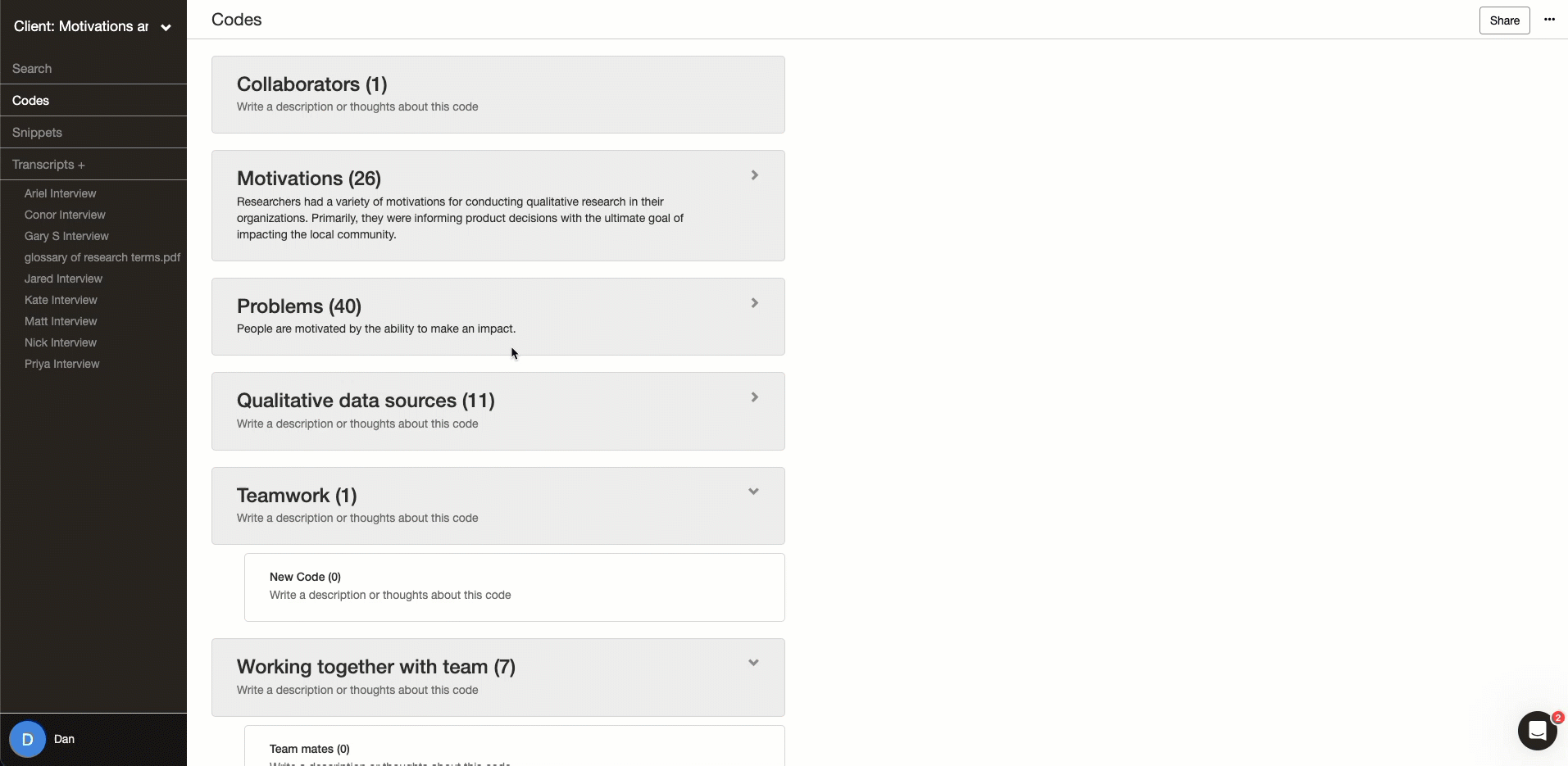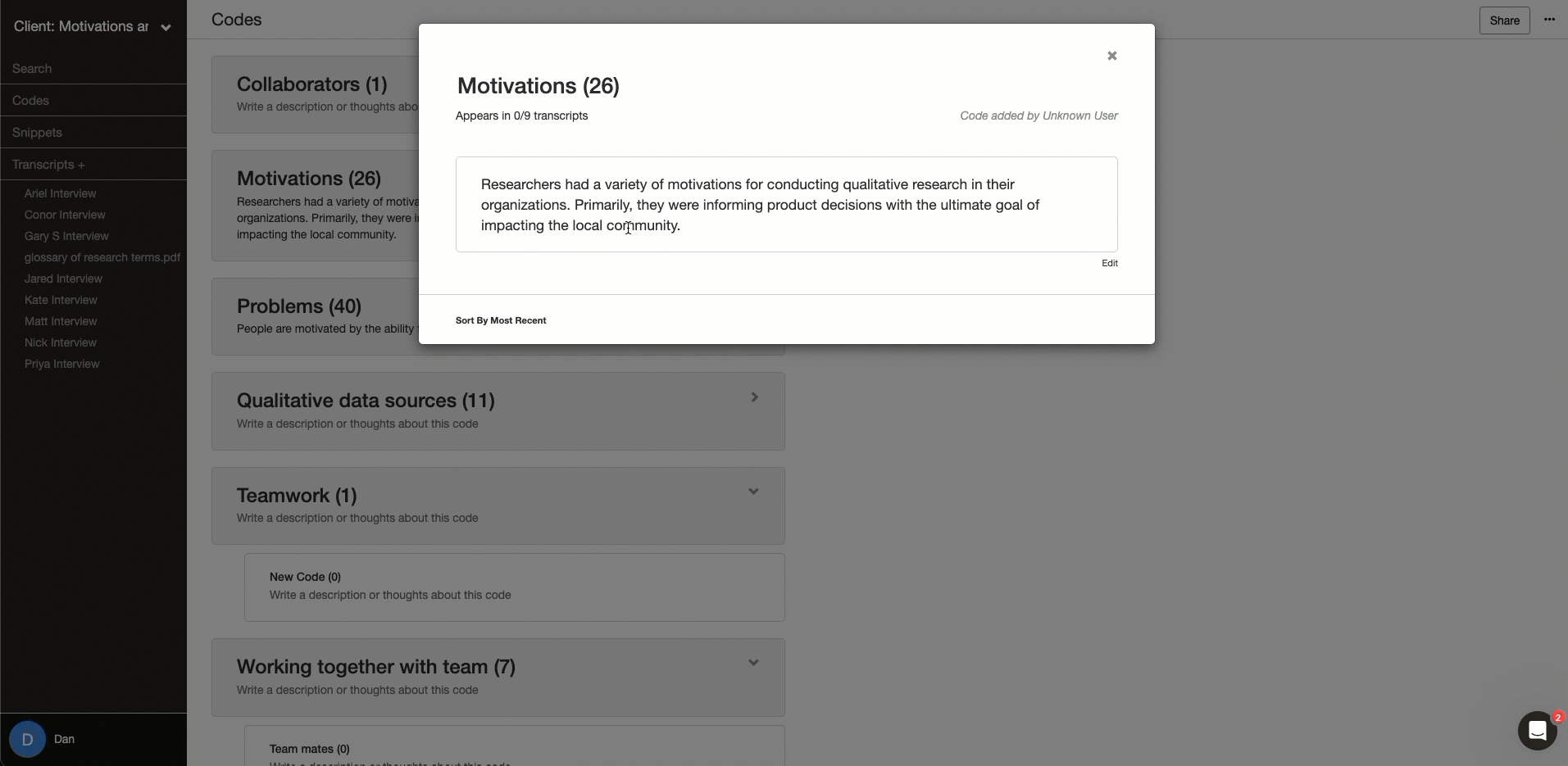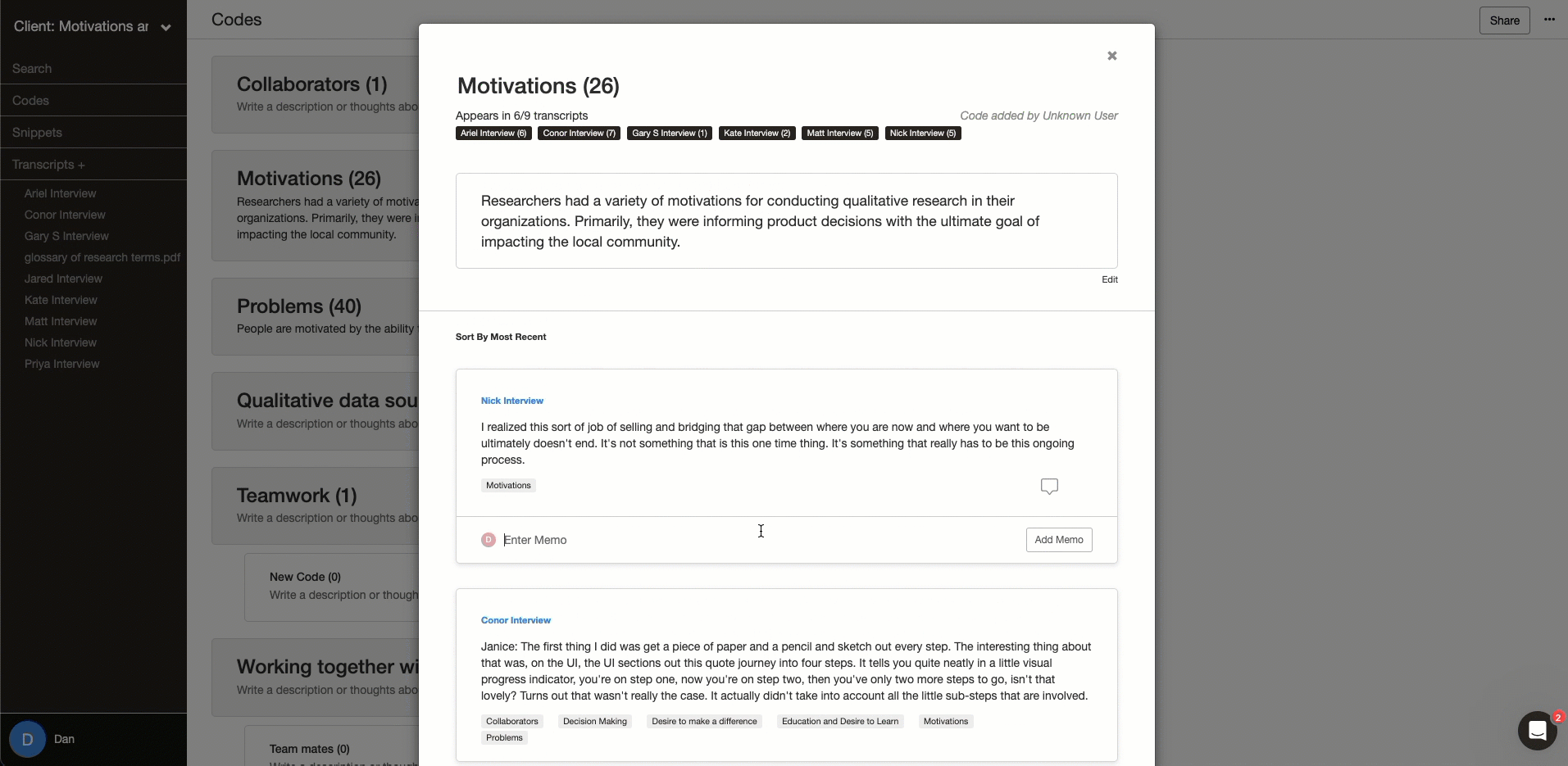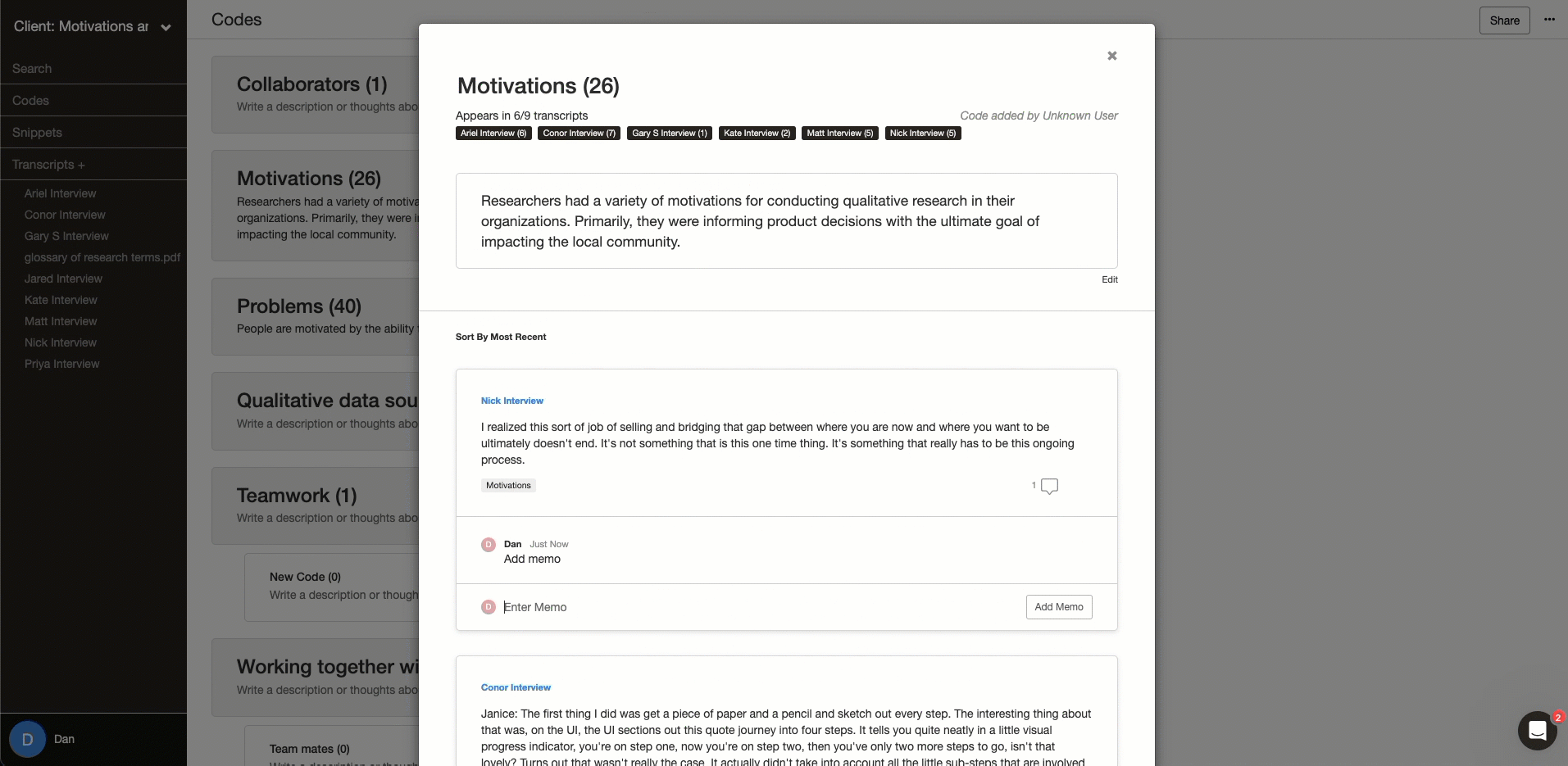
Ability to hide how others coded
You need a tool that enables multiple people to code on the same data set without having to duplicate projects but still allows you to code independently. This allows your team to analyze the data separately, but then bring that analysis together. Delve has a feature called “Coded by Me” that does just this.
If you are doing consensus coding or intercoder reliability, you’ll want to code the same transcript as other people, but you don’t want to see what they have coded until you are done.
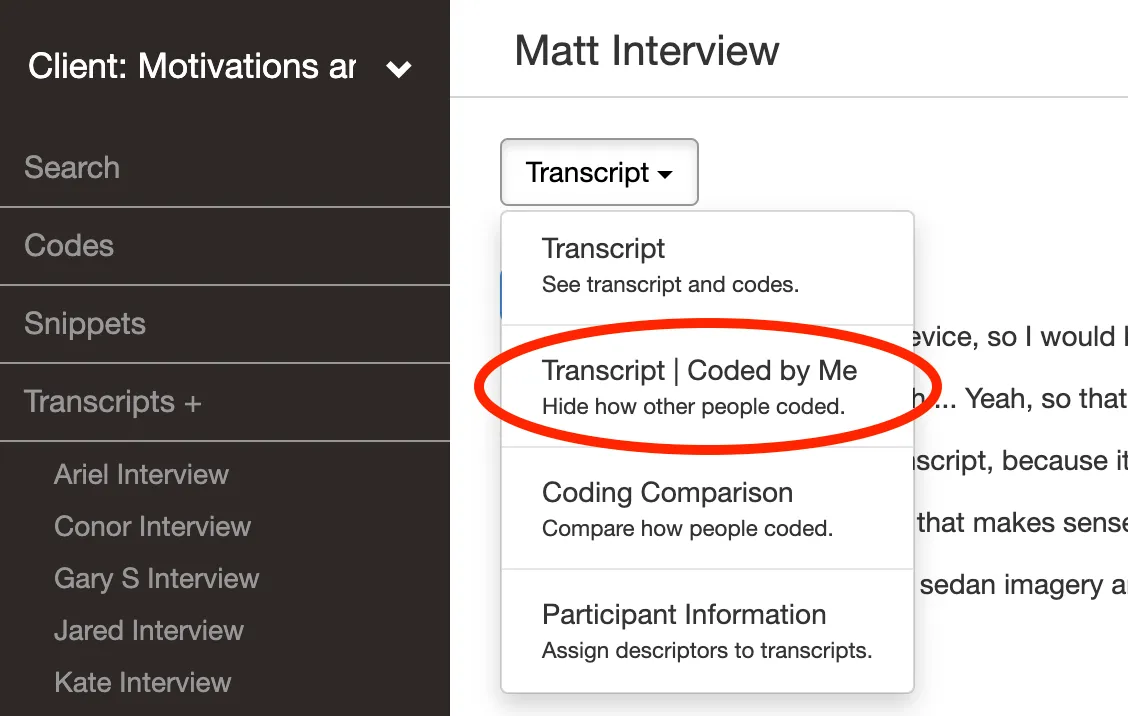
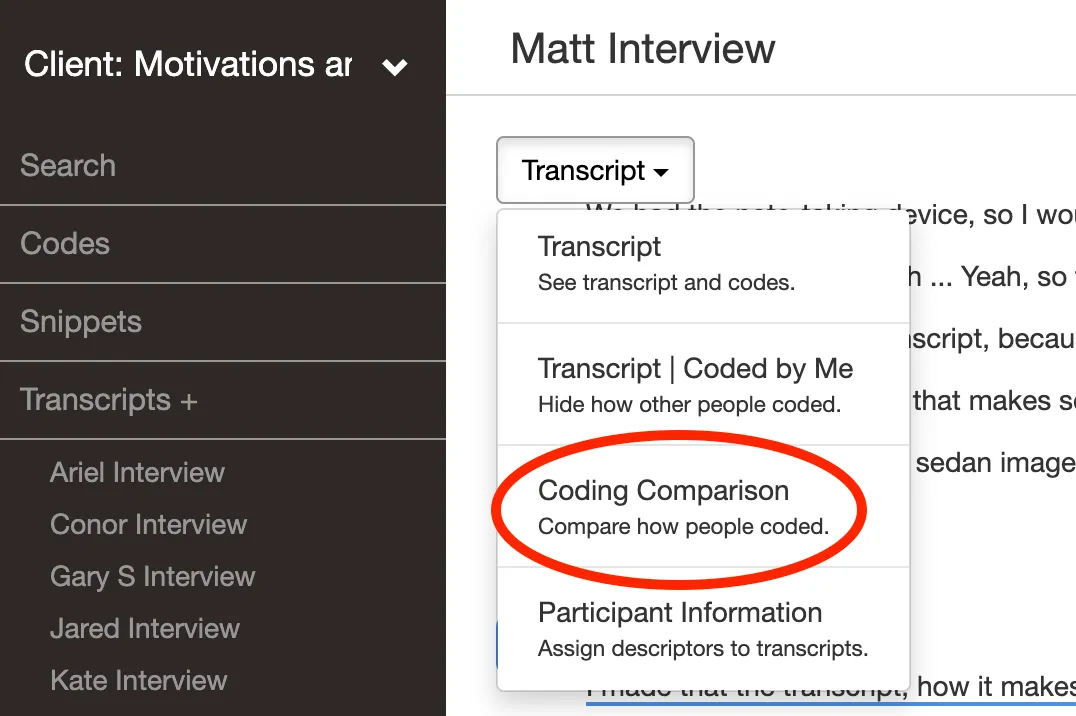
Ability to compare how group members coded
After your group codes the same transcript, you’ll want to compare how they coded. Look for a tool that enables you to easily see these differences. Delve has a “Coding Comparison” page where you can see two coders’ codings side by side.
Calculates intercoder reliability
If you’re taking an approach where you need to calculate your intercoder reliability score, then find a tool that can calculate this for you automatically. Intercoder reliability scores can be cumbersome to calculate manually, so software that does this automatically will save you a lot of time.
The best qualitative coding tool for collaboration
Everything in this guide — coding the same transcripts, comparing how your team coded, building consensus, and checking intercoder reliability — is built into Delve. It’s cloud-based, easy to learn, and made for research teams, with a 14-day free trial.
“We were up and running with Delve within minutes. It was very intuitive to use, with very quick setup. We were able to easily collaborate and facilitate our thematic analysis process without a steep learning curve and at a very reasonable price.” — Read the review
References
- Richards, K. A., & Hemphill, M. A. (2018). A practical guide to collaborative qualitative data analysis. Journal of Teaching in Physical Education, 37(2), 225–231. https://doi.org/10.1123/jtpe.2017-0084
- “CNPwebinar040 Coding in Teams - Salmona & Grummert” YouTube, uploaded by Christina Silver, 11 July 2023, https:// youtu.be/hntFBeP23Vg
- Delve, Ho, L., & Limpaecher, A. (2023c, June 14). Collaborative Thematic Analysis in Qualitative Research https://delvetool.com/blog/collaborative-thematic-analysis
- Delve, Ho, L., & Limpaecher, A. (2023c, April 6). What Is Consensus Coding and Split Coding in Qualitative Research? https://delvetool.com/blog/consensus-coding-split-coding
- Delve, Ho, L., & Limpaecher, A. (2023c, March 27). What Is Researcher Triangulation in Qualitative Analysis? https://delvetool.com/blog/researcher-triangulation
- Delve, Ho, L., & Limpaecher, A. (2021c, June 08). What is Peer Debriefing in Qualitative Research? https://delvetool.com/blog/peerdebriefing
- Delve, Ho, L., & Limpaecher, A. (2023c, April 26). Inter-coder reliability https://delvetool.com/blog/intercoder
Cite this blog post:
- Delve, Ho, L., & Limpaecher, A. (2023a, August 21). Guide to Collaborative Qualitative Analysis https://delvetool.com/blog/collaborative-qualitative-analysis