
This is part of our Guide To Collaborative Qualitative Analysis | Start a Free Trial of Delve | Take Our Free Online Qualitative Data Analysis Course
When you’re doing qualitative research as a team, things can get messy fast. Everyone brings their perspective, interpretation style, and insights to the table. While this variety adds depth to your analysis, it raises an important question: How do you know if everyone’s working from the same playbook and applying your codebook consistently? That’s where consensus coding and split coding come in.
-
Consensus coding is when you and your team code the same transcripts and compare results one to one. This method is more rigorous but also more time-consuming.
-
Split coding is when your team splits up their transcripts and codes them separately. Each transcript is discussed but with less attention given to each one – shortening the process.
These collaborative qualitative coding methods help your team develop a shared understanding of your data while offering results others know they can trust. But before we dig into how and when to use consensus and split coding, let’s lay some groundwork about doing team research–and some of the best tools for the job.
Quick overview: Staying aligned during collaborative coding
Qualitative data is inherently subjective. When you’re trying to understand it as a collective group, the same passage can hold different meanings for different researchers. That’s why we need systematic approaches to work with these interpretations while maintaining analytical rigor. Consensus coding and split coding help democratize these different interpretations in a structured way.

Say that you and your research team are analyzing interview transcripts about student experiences during remote learning. One of you might focus on technical challenges, like unstable internet connections, while another picks up on emotional responses, like isolation and stress. Both perspectives are valuable because they might reveal important patterns in your data, but how do they both translate into one codebook?
Here’s where research teams commonly face challenges:
-
Maintaining consistent interpretation of complex, subjective data
-
Managing potential bias when analyzing sensitive topics
-
Balancing different disciplinary perspectives in coding
-
Capturing a variety of interpretations while maintaining systematic analysis
It takes consistent, reliable coding practices across your team to address these challenges. After all, your analysis is only as strong as your team’s ability to apply codes consistently – what qualitative researchers call intercoder reliability. Without knowing how everyone on your team is seeing your data, you risk missing valuable insights or introducing unintended bias into your findings.
What is team coding—and why does consensus and split coding help?
At its core, qualitative coding is how we tag and organize meaningful patterns in our data. It can get incredibly challenging when you code with others who bring their lens to the analysis. But good collaborative coding (and the degree to which people trust you) goes beyond creating labels – it’s about making sure everyone applies your codebook consistently.
![[Delve Tutorial] How to Code](https://i.ytimg.com/vi/IhQmctWTbbo/maxresdefault.jpg)
Key aspects of team-based coding
-
Clear code definitions in your codebook everyone agrees on
-
Regular team discussions about everyone’s interpretation
-
A system to check for coding consistency (consensus and/or split coding)
-
Recording memos to explain the decision-making process
-
Coding tools to keep everyone coordinated and aligned
For instance, if your team is studying organizational change, you need to agree on what counts as “resistance” versus “adaptation” in your codebook. If a respondent mentions workarounds, is that the former or the latter? Different team members might interpret the same interview passage quite differently based on their background and experience. You need a transparent audit trail of memos to explain these decisions!
Consensus and split coding help your team track the process through individual memos (for coding decisions and initial insights) and a shared research journal (for inconsistencies and team discussions). Though the work gets messy, having a centralized coding tool like Delve keeps your personal notes and collective documentation organized.
Consensus vs. split coding: Two paths to team alignment

Consensus and split coding help explain your team’s coding decisions and intercoder reliability measurements. Think of these tools and your shared research journal as quality assurance for your codebook. They help balance the inherent subjectivity of qualitative coding by reducing or clearing up differences in how your team applies and perceives codes. A benefit of using a tool like Delve is everyone can measure their work in just a few clicks:
Your research journal is a place where you document the reasoning behind coding decisions, track shifts in interpretation, and capture the bigger picture as your analysis unfolds. Beyond just keeping notes, it’s about maintaining a clear, traceable record of how your team’s understanding evolves over time.
Remember our study about organizational change? Those different perspectives and questions about when to use “resistance” versus “adaptation”? That’s precisely where these two coding approaches help your team work more systematically to incorporate different perspectives and interpretations.
Building understanding through consensus coding
Consensus coding means your whole team analyzes the same transcripts or other data and then meets each week or two to compare notes. For example, multiple researchers code the same transcript about organizational change interviews and then discuss why someone coded a passage as “upward mobility” while another saw a “glass ceiling.” Along with your memos, your research journal tracks anything from coding inconsistencies to new insights. It takes more time but builds a strong shared understanding.

📌 When to use consensus coding
-
New teams: Helps establish shared coding practices and build team trust
-
Complex data: Perfect for nuanced content where interpretations can vary widely
-
Training: Great for getting new researchers up to speed with your approach
-
High stakes: When you need to demonstrate reliable, rigorous analysis
-
Framework building: Essential for developing your initial coding approach
📌 How to do consensus coding
Each researcher codes the same transcripts with the pre-defined codebook.
-
They review each transcript and compare results during check-ins.
-
They also review the research journal to flesh out any discrepancies, disagreements, or differences that surface before moving on to the next iteration.
-
They repeat the process until all the data is coded and the codebook is finalized.
Consensus coding is helpful here as it helps establish strong intercoder reliability, making your results more trustworthy for your readers. Through direct discussion and comparison, your team builds a shared understanding that strengthens the credibility of your findings.
Scaling up with split coding
Once your team has that strong foundation and everyone is on the same page, split coding lets you divide and conquer your materials while staying aligned through regular check-ins. Most teams start with consensus coding to build that shared understanding, then shift to split coding to save time by splitting up the workload. You can now code different sections because everyone has reached a consensus.
Remember that split coding is a trade-off - you code faster, but you might miss out on the quality checks that come with having multiple eyes on each transcript. Since you’re dividing up the work, you’ll need to rely more heavily on your initial groundwork. Those early consensus sessions and clear coding rules. That’s why it’s so important to build a solid foundation before making the switch.

📌 When to use split coding
-
Established teams: Your group already has strong coding alignment
-
Larger projects: Efficiently handle bigger datasets
-
Time pressure: Meet deadlines without sacrificing quality
-
Experienced coders: Leverage your team’s expertise
-
Clear framework: Your coding approach is well-defined
📌 How to do split coding
-
Each team member codes different transcripts with the pre-defined codebook.
-
Coders then meet to review each coded excerpt in the codebook. Using the research journal, they flesh out any discrepancies, disagreements, or differences that surface.
-
The team eventually comes to a consensus threshold and finalizes the codebook.
Team coding: A practical guide to consensus and split coding
Remember those different interpretations of “resistance” versus “adaptation” we discussed? Let’s walk through how to handle these challenges, building from initial setup to efficient team coding.
1. Set clear foundations
Strong team coding starts with good preparation and organization. Before diving in, you should establish clear ground rules and processes that everyone understands and agrees to follow.
Essential setup steps
-
Create detailed code definitions that everyone can access. These should be brief descriptions, examples, and context that help clarify when to use each code.
-
Schedule regular team meetings – consistent check-ins prevent drift in how people interpret and apply codes.
-
Establish your communication channels – decide how you’ll share updates and handle quick questions between meetings.
-
Define everyone’s responsibilities – clarifying who’s doing what helps prevent confusion and duplicate work.
-
Create a clear process for handling disagreements – you’ll need this when team members interpret data differently.
2. Build agreement through consensus
Start with consensus coding to build strong alignment. This initial investment in building shared understanding pays off in more consistent analysis later, letting you confidently split the workload and shorten your timeline.
Begin with:
-
Everyone codes the same materials independently – this reveals different interpretations early on.
-
Meet to compare how different team members coded the same passages – like how different researchers might interpret the “glass ceiling” example.
-
Discuss why team members coded things differently – these discussions tend to reveal assumptions you should all address.
-
Refine your code definitions based on these discussions – your codebook should evolve as your team’s understanding deepens.
-
Document decisions in your research journal – capture what you decided and the reasoning behind each choice.
-
Remember, all qualitative coding is iterative – you’ll likely need to revisit and refine your codes several times as your team’s understanding of the data evolves.
Your research journal is key here. It should tell the story of how your team’s understanding evolved. By noting why you categorized specific behaviors as “resistance” rather than “adaptation,” you’re creating a valuable reference for future coding decisions.
3. Track progress and stay aligned
Maintaining consistency is an ongoing process. Regular check-ins and clear documentation are essential to keeping everyone on the same page as your analysis develops.
Key tracking practices:
-
Compare coding patterns regularly - look for areas where team members are coding differently and discuss why
-
Document team discussions thoroughly - your research journal should capture both decisions and the reasoning behind them
-
Record areas of disagreement and their resolution - these often reveal important nuances in your data
-
Update your shared codebook as needed - treat it as a living document that grows with your understanding
-
Keep detailed memos about key decisions - explain why certain interpretations were chosen over others
4. Transition to split coding
Once your team shows strong alignment, you can switch to split coding for efficiency. Think of this transition as transitioning from training wheels to riding freely. You’ve built the foundation through consensus, and now you can work more independently while staying coordinated.
Making the transition work:
-
Divide remaining materials strategically - consider team members’ strengths and experience
-
Keep regular check-in meetings - these become even more important when working separately
-
Maintain detailed research journal entries - document your thinking process as you code independently
-
Record new questions as they arise - don’t wait for meetings to note potential issues
-
Conduct periodic cross-checks - randomly review each other’s coding to ensure consistency
Common challenges of consensus and split coding (and solutions)
Team coding offers tremendous benefits, but it also comes with challenges. Addressing these issues proactively saves time and makes your analysis more robust and trustworthy. Here’s how to navigate these obstacles using Delve to streamline your entire research process.
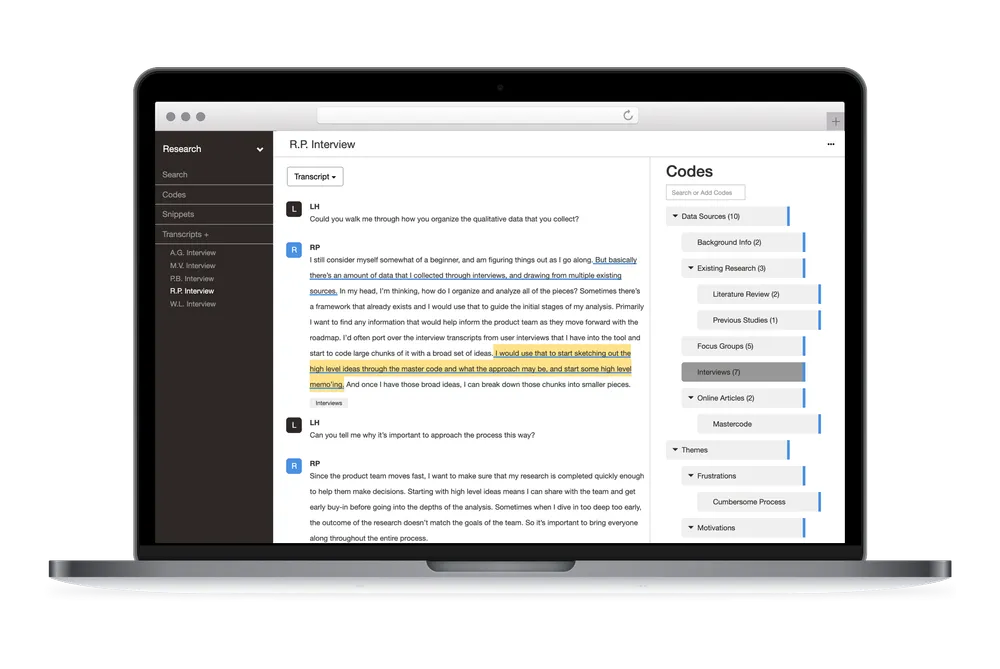
Managing different interpretations
When working with a team, it’s natural to interpret data differently based on their backgrounds and experiences. In fact, that variety is why collaborative qualitative research is such a powerful coding strategy. However, using multiple coders only strengthens your findings if your team can code consistently.
Solution: Regular team discussions resolve discrepancies and spur shared understanding. Delve memos let your team document their thought processes directly alongside specific codes, making it easy to track how interpretations evolve. Use Delve’s side-by-side coding comparison feature to review how different team members have coded the same data, enabling transparent discussions about discrepancies.
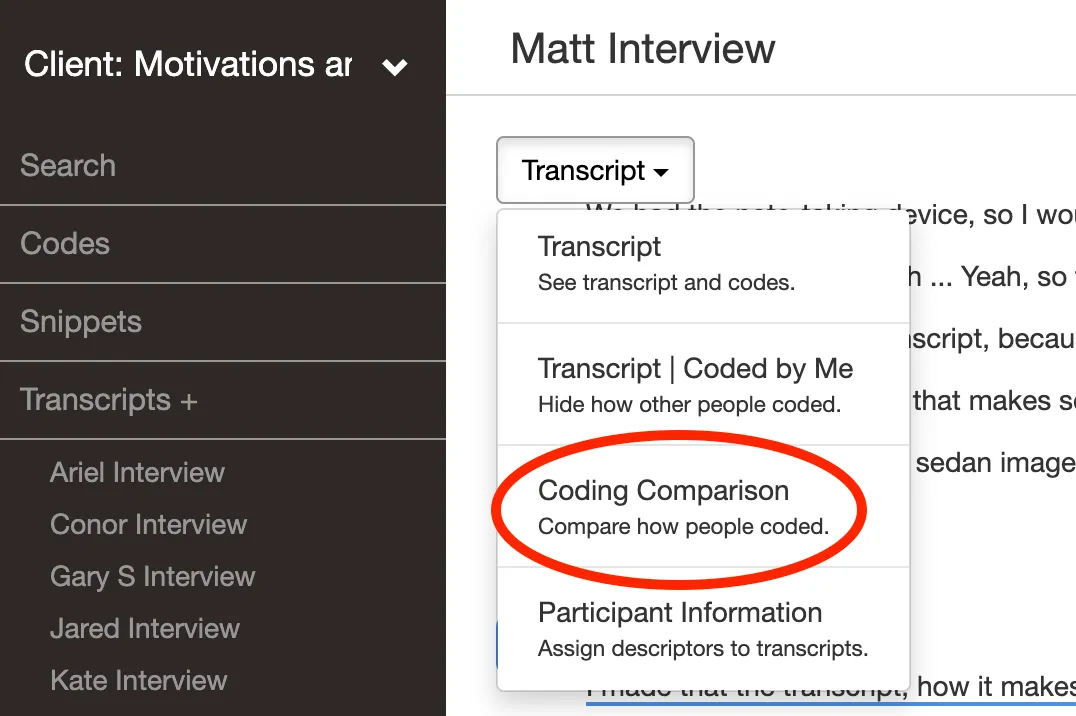
Maintaining consistency with other coders
As team members work independently, coding patterns can drift, leading to inconsistencies that undermine the reliability of your analysis.
Solution: With Delve, your shared codebook ensures all team members can access the most up-to-date data and code definitions. You can easily make updates and communicate changes in real-time, minimizing the risk of misaligned coding. Schedule alignment meetings to check for drift and use your memos and shared research journal to trace when and why specific changes were made to codes.
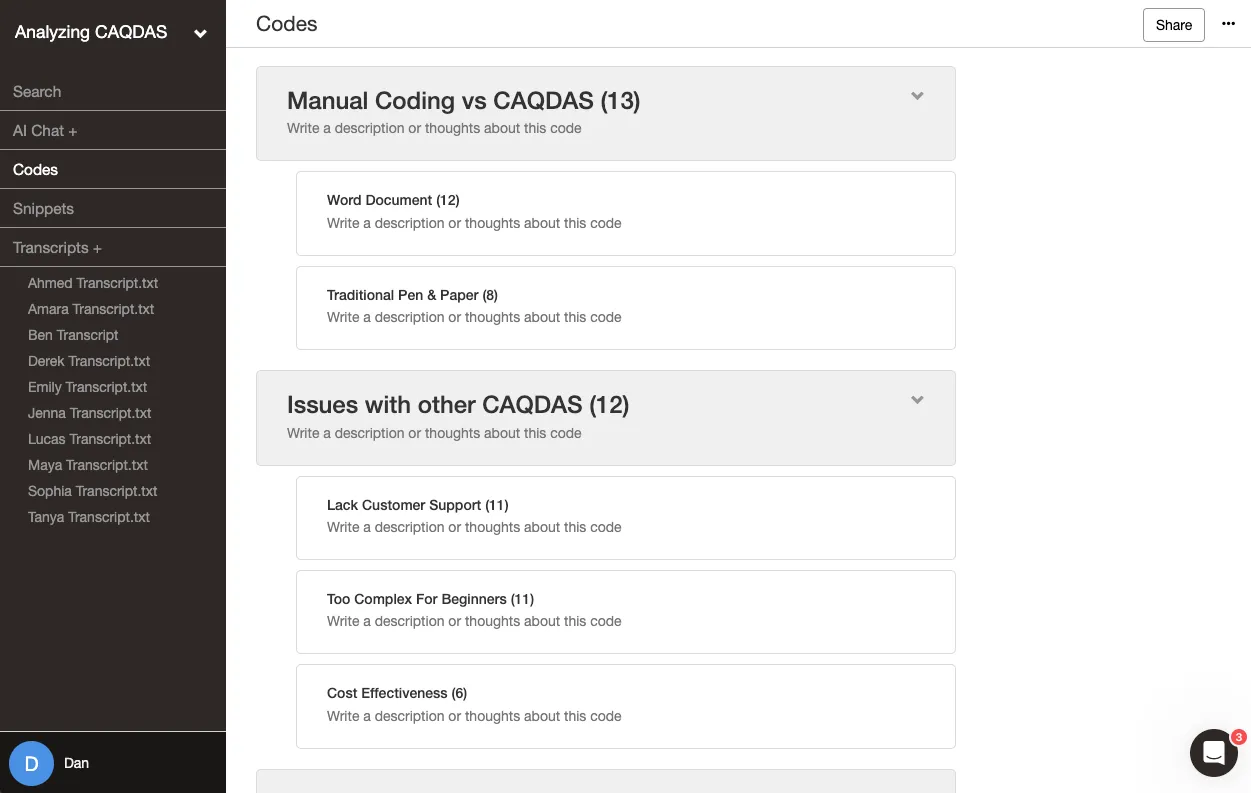
Coordinating remote research teams
Remote collaboration can make it challenging to maintain alignment, especially when team members are in different time zones or using disparate systems.
Solution: Delve’s web-based platform bridges geographic gaps by allowing teams to work on the same project from anywhere. Features like real-time updates and team-sharing options make it simple to keep everyone aligned. With just a few clicks, you can add team members to your project, ensuring they have immediate access to the data, memos, and codebooks they need.
Simple peer debriefing and feedback
Peer debriefing is a great way to strengthen the analysis when working collaboratively. However, managing this feedback can become overwhelming without the right tools.
Solution: Delve simplifies peer review by enabling seamless sharing of team projects. Whether inviting an external reviewer or sharing work internally, you can use the hide-coding feature to temporarily hide other team members’ coding decisions. This allows reviewers to analyze the data independently and leads to more unbiased feedback.
Simplify and align your team’s coding process
Overcoming these challenges requires clear communication, systematic workflows, and top tools. Delve makes it easy for your team to be consistent, aligned, and focused on producing meaningful insights.
-
Use side-by-side coding comparisons to address and resolve differences transparently.
-
Leverage shared memos and codebooks to keep your team aligned across projects.
-
Simplify peer review with easy project sharing and tailored visibility options.
-
Enhance collaboration with real-time updates and integrated memo systems.
By addressing common pain points with features designed for collaborative qualitative analysis, Delve empowers your team to work efficiently and effectively, no matter where they are. Click below for your free 14-day trial – no commitment. Cancel anytime.
References
-
Hemphill, M. A. & Richards, K. A. R. (2018). A practical guide to collaborative qualitative data analysis. Journal of Teaching in Physical Education, 37(2), 225–231. https://doi.org/10.1123/jtpe.2017-0084
-
Himanshu Zade, Bonnie Chinh, Abbas Ganji, and Cecilia Aragon. 2019. Ways of Qualitative Coding: A Case Study of Four Strategies for Resolving Disagreements. In Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems (CHI EA ‘19). Association for Computing Machinery, New York, NY, USA, Paper LBW0241, 1–6. https://doi.org/10.1145/3290607.3312879
-
Shenton, A.K. (2004). Strategies for ensuring trustworthiness in qualitative research projects. Education for Information, 22, 63–75. doi:10.3233/ EFI-2004-22201
Cite This Article
Delve, Ho, L., & Limpaecher, A. (2025, February 19). What Is Consensus Coding and Split Coding in Qualitative Research? https://delvetool.com/blog/consensus-coding-split-coding